Unix System Programming
(last update: Tue Sep 13 20:36:20 CEST 2016)
1 Course Information
1.1 Instructor
César Rodríguez (http://lipn.univ-paris13.fr/~rodriguez)
1.2 Syllabus and Program
Day 1:
- gcc, make, vi
- Program arguments and environment
- File I/O
Day 2:
- Process management
- Pipes
- Signals
Day 3:
- Sockets
1.3 Additional material
1.4 Evaluation of your code
Here are some criteria that will be taken into account for the evaluation of the source could that you are expected to submit in this course:
- Homogeneous and reasonable indentation and spacing (paragraphs, empty lines, spaces between words).
- Your code is as simple as possible, but not simpler.
- The code is clear, easy to read.
- Your code is robust and well tested. It rather displays error messages complaining about non-treated corner cases than it produces run-time crashes (for instance, segmentation faults).
- You use comments to explain your code. You are strongly adviced to structure your code in paragraphs, and introduce every paragraph with a one-line comment.
1.5 How to Submit Exercises / Code for Evaluation
You are expected to submit your source code using the ENT. Deadlines on September 19 and October 10, 2016.
Log in using your University user and password
Naviage to the online version of this course:
Accueil > Mes cours > Institut Galilée > Ingénieurs > Ingénieurs Télécom et Réseaux an3 > Système et programmation Unix - TELEC3
There is two links under the section "Exercices à rendre". Use them to submit the appropriate homework.
2 Compiling C Code
2.1 Getting help
- An online reference for the C language:
- The manual pages, both from the terminal and online:
- The GNU C library manual:
- A quick tutorial on the C language:
2.2 System calls
- Specific procedure, as processor needs to switch to supervisor mode
- The standard C library provides C-wrappers
- Documented in section 2; see also section 3 and section 7
- 380 system calls for Linux 3.2.0, see syscalls(2)
2.3 Error handling
System calls almost always return -1 (or NULL) when an error occurs
C library makes available an explanation through variable
extern int errno;
defined in <errno.h>, see errno(3)
| Variables | errno(3) |
| Functions | strerror(3), perror(3) |
| See also | err(3) (non-standard BSD functions, but very handy) |
2.4 First example
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <string.h>
int main(int argc, char *argv[])
{
int fd, errnum;
fd = open ("fjaksdjfsdklfjdsklf", O_RDONLY);
if (fd < 0)
{
/* at this point, quite probably, errno == ENOENT */
errnum = errno;
printf ("Errror, I cannot open the file\n");
printf ("errno is '%d'\n", errnum);
printf ("strerror is '%s'\n", strerror (errnum));
exit (1);
}
printf ("The file exists!!\n");
exit (0);
}
- Use exit(3) (or simply return from the main function) to terminate the program. The return code of the program is the value passed to exit or returned from main (and later available in the $? shell variable ;)
2.5 Compiling with gcc
Assume you have a small project consisting on two C files, main.c, containing the main() function of the program, and aux.c, containing auxiliary code.
Compiling and linking with one command:
gcc aux.c main.c -o myprog
Compiling into object code + linking:
gcc -c aux.c # outputs aux.o gcc -c main.c # outputs main.o gcc aux.o main.o -o myprog
The advantage of the second method is that it requires compiling only the files that were modified since last compilation (+ linking)
Here are some frequent options:
-g -Wall -Wextra -O1, -O2, -O3 -lm -lMY_LIB -I INCLUDE_DIR -D MACRO=VALUE
2.6 Using make
Compiling your program by hand every time you modify the source code is cumbersome.
The tool make computes which parts of a program need to be recompiled and calls the compiler accordingly
Information about the source code is in a file named Makefile (or makefile)
Target-oriented rules of the form:
target : prerequisite1 prerequisite2 <TAB> shell commands using the prerequisites and generating the target <TAB> more shell commands
Observe that the commands need to be prefixed with a tab (!)
The target of the first rule in the Makefile becomes the default target
First example of a Makefile:
myprog: main.c aux.c
gcc -Wall -Wextra -g aux.c main.c -o myprog
A more advanced version:
myprog: main.o aux.o
gcc main.o aux.o -o myprog
main.o: main.c
gcc -Wall -Wextra -g -c main.c
aux.o: aux.c
gcc -Wall -Wextra -g -c aux.c
Now the same but using pattern rules and automatic variables:
myprog: main.o aux.o
gcc $^ -o $@
%.o: %.c
gcc -Wall -Wextra -g -c $^ -o $@
In fact, make already knows the pattern rule above, not only for C but also for many other languages! Such built-in rules (which you can display running make -p) are parametrized with variables. An even shorter version of our Makefile would be:
CC=gcc
CFLAGS=-Wall -Wextra -g
myprog: main.o aux.o
gcc $^ -o $@
Some frequently used options of make are
-n -j N -p
3 File I/O
| System call | Description |
|---|---|
| open(2), creat(2) | open and possibly create a file or device |
| close(2) | close a file descriptor |
| read(2) | read from a file descriptor |
| write(2) | write to a file descriptor |
| truncate(2), ftruncate(2) | truncate a file to a specified length |
| lseek(2) | reposition read/write file offset |
| stat, fstat(2), lstat | get file status |
| remove | remove a file or directory |
| mkdir | create a directory |
| dup, dup2, dup3 | duplicate a file descriptor |
| sync, syncfs | commit buffer cache to disk |
| fsync, fdatasync | synchronize a file's in-core state with storage device |
| ioctl | control device |
| mmap, munmap | map or unmap files or devices into memory |
| msync | synchronize a file with a memory map |
- Example 1: mmap.c, showing how to use mmap(2) to load a newly created file in read/write access mode
- Example 2: read-copy.c showing how to open one file (path given as argument) and how to write (to the standard output) the contents of the file
- Example 3: stdin-stdout.c showing how to copy data from the standard input to standard output
Exercises: ARGENV, GETPUT, COPIE, NEWCAT from here.
4 Processes
Process management:
| System call | Description |
|---|---|
| getpid(2), getppid(2) | get process identification |
| getuid(2), geteuid | get user identity |
| setuid | set user identity |
| setgid | set group identity |
| fork(2) | create a child process |
| exit(3) | cause normal process termination |
| wait(2), waitpid, waitid | wait for process to change state |
| execl(3), execv(3) | execute a file |
| system(3) | execute a shell command |
- Example 1: fork-simple.c, showcasing how to use fork and wait.
- Exercises: 1 (exec), 2 (fork), 3 (stdout redirection) from here.
Basic thread management, see pthreads(7):
| System call | Description |
|---|---|
| pthread_create | create a new thread |
| pthread_attr_init, pthread_attr_destroy | initialize and destroy thread attributes object |
| pthread_detach | detach a thread |
| pthread_exit | terminate calling thread |
| pthread_join | join with a terminated thread |
| pthread_mutex_destroy, pthread_mutex_init | destroy and initialize a mutex |
| pthread_mutex_lock, pthread_mutex_trylock, pthread_mutex_unlock | lock and unlock a mutex |
- Example: pthreads.c, illustrating the creation of two threads; observe how we use the errno variable and profit from the err routine to print possible errors
5 Pipes
| System call | Description |
|---|---|
| pipe(2) | create a half-duplex pipe |
| popen, pclose | pipe stream to or from a process |
| mkfifo | make a FIFO special file (a named pipe) |
Observe that pipe(2) is a half-duplex mechanism, data flows in only one direction.
- Example: fork-exec-pipe.c, showing how to use a pipe to read, from a parent process, the standard output of a child process
- Exercises: 4 (simple pipe) from here.
6 Signals
- Unreliable in early implementations
- Problem of malloc
- Problem of handling EINTR
Signal management:
| System call | Description |
|---|---|
| sigaction(2) | examine and change a signal action |
| kill(2) | send signal to a process |
- Example 1: sigaction.c showcasing the use of sigaction and the consequences of signals on ongoing system calls.
- Exercises: 5 (mykill), 6 (Ctrl+c) from here.
7 Network
Applications acces the network in a POSIX compliant system using the so-called sockets. POSIX sockets enable applications to initiate, manage and terminate TCP connections and UDP streams. The sockets API also gives access to other forms of interprocess communication different than networking, such as, for instance the so-called UNIX domain sockets, which we will not study here.
You already know that almost everything in Unix is, or can be seen, as a file. Sockets "are" also files, and some primitives that you already used for files can also be used with sockets, such as read(2) or write(2).
In this chapter we concentrate on using the sockets API for accessing the Internet protocols (TCP, UDP, and IP).
7.1 Flow of Operations
The following figure illustrates the flow of operations that client and server program shall carry out to operate a TCP connection.
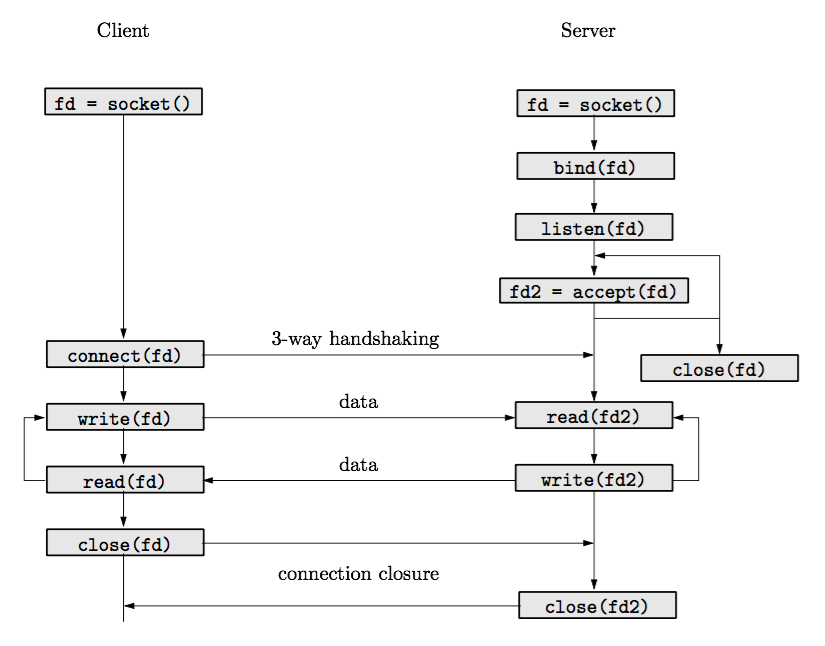
Both server and client will initially create a socket, specifying that they want to use the internet protocols (AF_INET), in particular a TCP connection (SOCK_STREAM) or a UDP stream (SOCK_DGRAM). This is achieved using the socket(2) system call.
The server will then bind(2) the socket to a service point, that is, a pair (IP address, port) to which the client can later connect.
When the server invokes listen(2), the socket is set as a listening socket. This means that it can only be used to derive new data sockets. No data will be transmitted through a listening socket.
The server just after calls accept(2). This primitive blocks the process until the machine receives a TCP connection request. This will happen when the client executes connect(2). The underlying operating system will run here the famous TCP three-way handshake. Once completed, the system call accept(2) returns the control to the server. The returned value is a data socket (fd2 in the figure), that can now be used to transmit data.
Subsequent calls to write(2) and read(2) on the client or server will transfer/receive data to/from the connection.
It is easy to get confused and think that each data chunk writen with write(2) will be the exact block of data read on the other end. This is however incorrect. A TCP stream is best thought as a data pipe, where write(2) pushes data at one side and read(2) extracts data from the other side, without respecting in any way the "boundaries" created by the calls to write. Often, read will return as soon as any data is available. This may be triggered, for instance, by the arrival of an IP network packet encapsulating a TCP segment. Similarly, the "boundaries" created by the TCP segmentation algorithm (the actual TCP segments traveling through the network) will often not be the boundaries associated to the calls to write(2), although it may be the case (if, for instance, your application introduces large enough amounts of time between each write).
Calling close(2) at the client or server will close the connection in both ways. It is also possible to half-close the connection, closing only one direction but not the other. Use shutdown(2) for this.
Closing the connection at one side will trigger various events on the other side.
If one side closes and the other side writes, the process will receive the signal SIGPIPE, and the write will fail with error EPIPE. Recall that the default signal handler for SIGPIPE kills the application. You might want to change this default behaviour, using sigaction(2).
On the other hand, if one side closes and the other reads, read(2) will return 0 bytes, indicating an end of file (EOF) condition.
| System call | Description |
|---|---|
| socket(2) | create an endpoint for communication |
| bind(2) | bind a nam to a socket |
| listen(2) | listen for connections on a socket |
| accept(2) | accept a connection on a socket |
| connect(2) | initiate a connection on a socket |
| shutdown(2) | shut down part of a full-duplex connection |
| htonl(3), htons(3), ntohl(3), ntohs(3) | convert values between host and network byte order |
| send, sendto, sendmsg | send a message on a socket |
| recv, recvfrom, recvmsg | receive a message from a socket |
| getaddrinfo(3), freeaddrinfo, gai_strerror | network address and service translation |
| getsockopt, setsockopt | get and set options on sockets |
| select(2) | synchronous I/O multiplexing |
| poll(2), ppoll | wait for some event on a file descriptor |
7.2 A Client Example
- Full code: tcp-client.c, showing how to create a TCP client connecting to localhost:1234 and echoing to the connection whatever it reads from it.
The first step is creating a socket for using the TCP protocol. We achieve this using AF_INET and SOCK_STREAM:
#define BUFFS 1024
int main ()
{
int ret, ret2, fd;
struct sockaddr_in addr;
char buff[BUFFS];
fd = socket (AF_INET, SOCK_STREAM, 0);
if (fd == -1) err (1, "socket");
We now need to connect(2) the socket to the destination service host and port. We provide the address using a structure of type sockaddr_in. The first field stores AF_INET, meaning that we are providing an Internet address. Field sin_port stores the port and sin_addr stores the IP address.
We need to use the network byte order format, so we use the htonX functions:
addr.sin_family = AF_INET;
addr.sin_port = htons (1234);
//addr.sin_addr.s_addr = htonl (0x1f00001);
addr.sin_addr.s_addr = htonl (INADDR_LOOPBACK);
ret = connect (fd, (struct sockaddr *) &addr, sizeof (addr));
if (ret == -1) err (1, "connect");
printf ("We connected!\n");
Observe that the second argument for connect(2) is the size of the data structure containing the address, and that we cast the addr variable to the type sockaddr. This is due to the fact that the sockets API is generic, and the connect(2) function needs to deal with different address formats for different networks.
The next step is fairly obvious. We got the socket connected, and it now behaves like a regular file, where we can read and write. As usual we detect the EOF by checking the number of bytes returned by read(2):
while (1)
{
ret = read (fd, buff, BUFFS);
if (ret == -1) err (1, "read");
warnx ("read %d bytes", ret);
if (ret == 0) break;
ret2 = write (fd, buff, ret);
if (ret == -1) err (1, "write");
if (ret != ret2) errx (1, "partial write");
}
close (fd);
return 0;
}
7.3 A Server Example
- Example: tcp-server.c, showing how to create a TCP server that waits for new clients, send them a welcome message and immediately closes the connection.
7.4 Input/Output Multiplexing
Assume that you need to program a server to which multiple clients can connect. You will deal with one connection per client. Assume that 5 clients have already connected to your server. As soon as a client sends a request, your server needs to reply it. However, it is impossible to know in advance which client will send it first, and as a result, it is impossible to know which socket we should read first.
If we decide to read one at random and no data is present, the kernel will block the server until some data is received. If in the meantime another client's request reaches the server, your design will make the second client to wait unnecessarily until the request of the first client arrives and is processed.
Instead, Unix provides the system call select(2), or alternatively poll(2). Both can be used to solve our problem. The former one is perhaps more popular, and more material is available on the Internet. The latter one is less popular but is somehow easier to use. For this reason here we will study the second one.
The poll(2) system call receives a set of file descriptors. For each file descriptor we specify a bit indicating that
- (POLLIN) we want to know if calling read(2) on that file descriptor will return immediately (because the data has already been received);
- (POLLOUT) we want to know if calling write(2) on that file descriptor will return immediately (because there is enough space on the internal buffers)
When poll(2) returns, it indicates us back which file descriptors are ready for which operation.
The function receives three arguments:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
The first one is a vector of structures of type pollfd, one per file descriptor:
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
The field fd stores the file descriptor in question
Field events is a bitwise disjunction of the macros POLLIN or POLLOUT (more are available).
When poll(2) returns, the field revents contains one enabled bit for each operation which now will not be blocking (used the macros above to check which operation is available).
The argument nfds is the size of the vector fds, and timeout is the maximum number of milliseconds for which poll(2) will wait, or -1 to mean "infinite timeout".
Example: we are interested in reading from file descriptors 4 and 7, and writing in 9. We wait for 500ms at most before an event arrives:
int ret; struct pollfd pfds[3]; pfds[0].fd = 4; pfds[0].events = POLLIN; pfds[1].fd = 7; pfds[1].events = POLLIN; pfds[2].fd = 9; pfds[2].events = POLLOUT; ret = poll (pfds, 3, 500); if (ret == -1) ... // error if (ret == 0) ... // no file descriptor ready in 500ms if (pfds[0].revents & POLLIN) ... // we can read from 4 without blocking if (pfds[1].revents & POLLIN) ... // we can read from 7 without blocking if (pfds[2].revents & POLLOUT) ... // we can write to 9 without blocking
Example: poll.c, showing how to create a TCP client connecting to localhost:1234 and echoing to the connection whatever it reads from it.
7.5 Additional Examples
- Example: sock-thread.c, showing how to use two threads to read and write on a TCP socket