Unix System Programming
(Last update: Mon Sep 21 13:41:51 CEST 2015)
1 This Course
- Contact info:César Rodríguez <cesar.rodriguez@lipn.fr>
- Course web page:
- Source code examples (and Makefile):Available here.
- Some exercises:Available here.
1.1 Syllabus
- gcc, make, vi
- File I/O
- Process management
- Pipes
- Signals
- Sockets
2 Introduction
2.1 Getting help
- An online reference for the C language:
- The manual pages, both from the terminal and online:
- The GNU C library manual:
- A quick tutorial on the C language:
2.2 System calls
- Specific procedure, as processor needs to switch to supervisor mode
- The standard C library provides C-wrappers
- Documented in section 2; see also section 3 and section 7
- 380 system calls for Linux 3.2.0, see syscalls(2)
2.3 Error handling
System calls almost always return -1 (or NULL) when an error occurs
C library makes available an explanation through variable
extern int errno;
defined in <errno.h>, see errno(3)
| Variables | errno(3) |
| Functions | strerror(3), perror(3) |
| See also | err(3) (non-standard BSD functions, but very handy) |
2.4 First example
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <string.h>
int main(int argc, char *argv[])
{
int fd, errnum;
fd = open ("fjaksdjfsdklfjdsklf", O_RDONLY);
if (fd < 0)
{
/* at this point, quite probably, errno == ENOENT */
errnum = errno;
printf ("Errror, I cannot open the file\n");
printf ("errno is '%d'\n", errnum);
printf ("strerror is '%s'\n", strerror (errnum));
exit (1);
}
printf ("The file exists!!\n");
exit (0);
}
- Use exit(3) (or simply return from the main function) to terminate the program. The return code of the program is the value passed to exit or returned from main (and later available in the $? shell variable ;)
2.5 Compiling with gcc
Assume you have a small project consisting on two C files, main.c, containing the main() function of the program, and aux.c, containing auxiliary code.
Compiling and linking with one command:
gcc aux.c main.c -o myprog
Compiling into object code + linking:
gcc aux.c # outputs aux.o gcc main.c # outputs main.o gcc aux.o main.o -o myprog
The advantage of the second method is that it requires compiling only the files that were modified since last compilation (+ linking)
Here are some frequent options:
-g -Wall -Wextra -O1, -O2, -O3 -lm -lMY_LIB -I INCLUDE_DIR -D MACRO=VALUE
2.6 Using make
The tool make computes which parts of a program need to be recompiled and calls the compiler accordingly
Information about the source code is in the file Makefile (or makefile)
Target-oriented rules of the form:
target : prerequisite1 prerequisite2 <TAB> shell commands using the prerequisites and generating the target <TAB> more shell commands
Observe that the commands need to be prefixed with a tab (!)
The target of the first rule in the Makefile becomes the default target
First example of a Makefile:
myprog: main.c aux.c
gcc -Wall -Wextra -g aux.c main.c -o myprog
A more advanced version:
myprog: main.o aux.o
gcc main.o aux.o -o myprog
main.o: main.c
gcc -Wall -Wextra -g -c main.c
aux.o: aux.c
gcc -Wall -Wextra -g -c aux.c
Now the same but using pattern rules and automatic variables:
myprog: main.o aux.o
gcc $^ -o $@
%.o: %.c
gcc -Wall -Wextra -g -c $^ -o $@
In fact, make already knows the pattern rule above, not only for C but also for many other languages! Such built-in rules (which you can display running make -p) are parametrized with variables. An even shorter version of our Makefile would be:
CC=gcc
CFLAGS=-Wall -Wextra -g
myprog: main.o aux.o
gcc $^ -o $@
Some frequently used options of make are
-n -j N -p
3 File I/O
| System call | Description |
|---|---|
| open(2), creat(2) | open and possibly create a file or device |
| close(2) | close a file descriptor |
| read(2) | read from a file descriptor |
| write(2) | write to a file descriptor |
| truncate(2), ftruncate(2) | truncate a file to a specified length |
| lseek(2) | reposition read/write file offset |
| stat, fstat(2), lstat | get file status |
| remove | remove a file or directory |
| mkdir | create a directory |
| select(2) | synchronous I/O multiplexing |
| poll(2), ppoll | wait for some event on a file descriptor |
| dup, dup2, dup3 | duplicate a file descriptor |
| sync, syncfs | commit buffer cache to disk |
| fsync, fdatasync | synchronize a file's in-core state with storage device |
| ioctl | control device |
| mmap, munmap | map or unmap files or devices into memory |
| msync | synchronize a file with a memory map |
Example 1: mmap.c, showing how to use mmap(2) to load a newly created file in read/write access mode
Example 2: read-copy.c (correction given on 17/09/2015), showing how to open one file (path given as argument) and how to write (to the standard output) the contents of the file
- Exercises: ARGENV, GETPUT, COPIE, NEWCAT from here.
4 Processes
Process management:
| System call | Description |
|---|---|
| getpid(2), getppid(2) | get process identification |
| getuid(2), geteuid | get user identity |
| setuid | set user identity |
| setgid | set group identity |
| fork(2) | create a child process |
| exit(3) | cause normal process termination |
| wait(2), waitpid, waitid | wait for process to change state |
| execl(3), execv(3) | execute a file |
| system(3) | execute a shell command |
- Example 1: fork-simple.c, (given on 18/09/2015), showcasing how to use fork and wait.
Basic thread management, see pthreads(7):
| System call | Description |
|---|---|
| pthread_create | create a new thread |
| pthread_attr_init, pthread_attr_destroy | initialize and destroy thread attributes object |
| pthread_detach | detach a thread |
| pthread_exit | terminate calling thread |
| pthread_join | join with a terminated thread |
| pthread_mutex_destroy, pthread_mutex_init | destroy and initialize a mutex |
| pthread_mutex_lock, pthread_mutex_trylock, pthread_mutex_unlock | lock and unlock a mutex |
- Example: pthreads.c, illustrating the creation of two threads; observe how we use the errno variable to profit from the err routine to print possible erros
5 Pipes
| System call | Description |
|---|---|
| pipe(2) | create a half-duplex pipe |
| popen, pclose | pipe stream to or from a process |
| mkfifo | make a FIFO special file (a named pipe) |
- pipe(2) is half-duplex; the most common ipc
- Example: fork-exec-pipe.c, showing how to use a pipe to read, from a parent process, the standard output of a child process
6 Signals
- Unreliable in early implementations
- Problem of malloc
- Problem of handling EINTR
Signal management:
| System call | Description |
|---|---|
| sigaction(2) | examine and change a signal action |
| kill(2) | send signal to a process |
Example 1: sigaction.c (given on 18/09/2015), showcasing the use of sigaction and the consequences of signals on ongoing system calls.
- Exercises: KILLPROC, CTRL+C, EXECUTE, FOURCHE, (PIPE) from here.
7 Other Inter-Process Communication (IPC) Primitives
- Message queues: mq_overview(7)
- Shared memory: shm_overview(7)
- Semaphores: sem_overview(7)
- Unix domain sockets
8 Network
Network programming with POSIX sockets enables the initiation, handling and termination of TCP and UDP streams, among others. The interface primitives are thus coupled with the operations associated to these protocols.
The following figure illustrates the flow of operations that client and server shall carry out to operate a TCP connection.
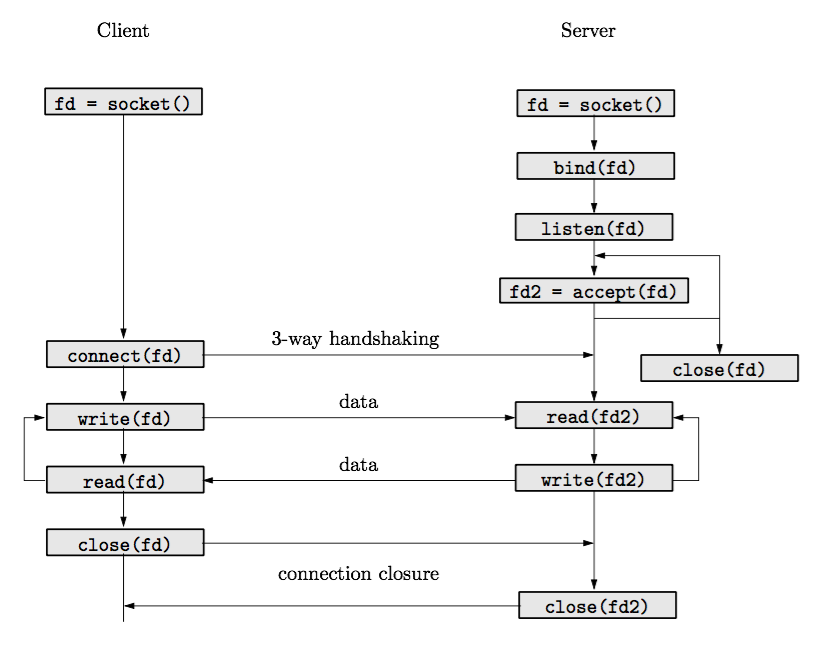
Both server and client will initially create a socket, specifying that they want to use the internet protocols (AF_INET), in particular a TCP stream (SOCK_STREAM). The server will then bind the socket to a service point, i.e., a couple (IP address, port) to which the client will later connect.
When the server invokes listen, the socket is set as a listening socket, that is, a socket that can only be used to derive new data sockets. No data will be transmitted through a listening socket. After calling accept, the server will block until a client executes connect. The return value of accept will be a new data socket (fd2 in the figure), that can now be used to transmit data.
Subsequent calls to write and read on the client or server will transfer data to the client or server. It is not true that the data chunk passed to write at one side of the connection will necessarily be the one that read returns at the other side. Each TCP stream is best thought as a data pipe, where write pushes data at one side and read extracts data from the other side. Often, read will return as soon as any data is available. This may be triggered, for instance, by the arrival of an IP network packet encapsulating a TCP segment. Realize that boundaries created the TCP segmentation algorithm will often not be boundaries associated to the write calls, although it may be the case. [1]
Invoking close at the client or server will close the connection in both ways. It is also possible to partially close the connection in any direction, using shutdown. Closing the connection at one side will trigger different events on the other side. If the other side writes, the process will receive the signal SIGPIPE [2], and write will fail with EPIPE. [3] If the other side reads, read will return 0 bytes, indicating an end of file.
| System call | Description |
|---|---|
| socket(2) | create an endpoint for communication |
| bind(2) | bind a nam to a socket |
| listen(2) | listen for connections on a socket |
| accept(2) | accept a connection on a socket |
| connect(2) | initiate a connection on a socket |
| shutdown(2) | shut down part of a full-duplex connection |
| htonl(3), htons(3), ntohl(3), ntohs(3) | convert values between host and network byte order |
| send, sendto, sendmsg | send a message on a socket |
| recv, recvfrom, recvmsg | receive a message from a socket |
| getaddrinfo(3), freeaddrinfo, gai_strerror | network address and service translation |
| getsockopt, setsockopt | get and set options on sockets |
- Example: tcp.c, showing how to create a TCP client connecting to localhost:1234 and echoing to the connection whatever it reads from it.
- Example: sock-thread.c, showing how to use two threads to read and write on a TCP socket
8.1 Exercise: The Command tcpcat
The goal of this exercise is writing a simplified version of the netcat(1) command. The output should be called tcpcat, and it will be able to both open TCP connexions as a client and act as a TCP server, with the following syntax and functionality:
- $ tcpcat HOST PORTwhere HOST is either an IP address or an URL, and PORT is a port number.
This command will open a connection to the port PORT of the host HOST. It will send anything written to its standard input and write on standard output anything received from the connection.
- $ tcpcat -l PORTwhere PORT is a port number.
This command will open a listening TCP socket accepting incoming connections from any network card. It will accept one client, will send to it anything read from its standard input, and will write to the standard output anything received from the connection.
Note: you do not have the right to use threads or processes to implement this program, use either poll(2) or select(2).
8.2 Exercise: mini-httpd, a Simple Concurrent Web Server
The Hypertext Transfer Protocol (HTTP) is the protocol that lies at the foundations of data communication in the Internet. It is a request-response protocol. It enables a client to manipulate a resource (usually a file) in the server. Request and reply messages are formatted using plain text.
In this exercise we will implement a very simple HTTP server capable of serving the files present in the file system. It will have the following features:
- It will fork(2) a process to deal with every client connecting to the server. The new process will receive the client request and reply appropriately, exiting immediately after.
- It will read a configuration file located at the $HOME directory, and called mini-httpd.conf. The server will exit if such file is not present.
- Upon reception of the signal SIGUSR1, the server will re-read the configuration file and apply the new settings.
8.2.1 HTTP Protocol: Simplified Technical Presentation
Every HTTP request message contains a method and a resource. A method is an action to perform on the resource. The most common method is the GET method, which tells the server to send the resource to the client. Other methods (such as HEAD, POST) are out of the scope of this exercise. Our server will only implement the GET method.
Here is an example of a request message using the GET method and the resource path/to/file.html:
GET path/to/file.html HTTP/1.1 Host: localhost:1234 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:40.0) Connection: keep-alive
The GET word identifies the method being used. It is followed by a space and then the path to the resource, then another space, the keyword HTTP/ and the version of the protocol being used. Our server will always reply with the version number 1.0 (even if the client uses 1.1, as in this case).
Request, and reply, messages can optionally include headers. In the above example the Host, User-Agent, and Connection headers have been included. Our server will ignore all headers present in the request message.
Every line in the request message is terminated by the characters \r\n, ASCII codes 0x0D and Ox0A. This is commonly known as the MSDOS end-of-line characters. The request message terminates by a double MSDOS end-of-line, that is the four characters:
\r\n\r\n
Once the server has processed the request it will send a reply message. Here is an example:
HTTP/1.0 200 OK Server: mini-httpd/0.1 Content-Type: text/plain Here is the content of the file requested by the client.
The HTTP/ string comes first, followed by the protocol version. Then a space followed by a numeric code called the status code (in this case 200), a space and a 1-line text message called the reason phrase (in this case OK). The Server and Content-Type headers follow, with their respective values. All lines are terminated by a MSDOS end-of-line, and the last header (if present) is followed by a double end-of-line.
An optional message body follows the double end-of-line. In the above example, the message body contains the file requested by the client. The server shall close the connection after sending the last byte of the message body.
8.2.2 Features of mini-httpd
Our server will only accept requests using the GET method. On reception of any other method, it will reply a status code 501.
It will ignore all headers included in a request message
It will use HTTP/1.0 replies
It will be able to reply the following status codes:
Status code Reason phrase 200 OK 404 Not Found 501 Not Implemented 500 Internal Server Error It will include the following header in all HTTP replies:
Server: mini-httpd v0.1
It will optionally include the header
Content-Type: <MIME type>
on those requests where the requested resource is a file whose extension is present in the following table:
Extension <MIME type> .pdf application/pdf .png image/png .jpeg image/jpeg .jpg image/jpeg .txt text/plain .html text/html Any other Do not include the Content-Type header You are free to extend your web server with other mime types, see here http://www.sitepoint.com/web-foundations/mime-types-complete-list/. (NB: the command file -i guesses the MIME file type of a given file.)
After starting, the server will load the configuration file $HOME/mini-httpd.conf (the $HOME variable is an environment variable). It will exit if the file cannot be read. The file will look like this:
port=8080 cwd=/home/cesar/httpd-root/
The variable port tells the server the port number on which it accepts new connections. The variable cwd provides an absolute path from which the relative paths provided in client request messages will be interpreted.
Upon reception of the signal SIGUSR1, our server will re-read the configuration file and apply the new settings.
Whenever the resource requested is a directory, mini-httpd will generate an HTML file and will send the header Content-Type: text/html.
For instance, assume that the directory path/to/dir is requested and it contains the following files:
$ ls -lha total 800 drwxr-xr-x 20 cesar staff 680B Sep 21 12:59 . drwxr-xr-x 14 cesar staff 476B Sep 21 02:30 .. -rw-r--r-- 1 cesar staff 319B Sep 9 15:30 Makefile drwxr-xr-x 15 cesar staff 510B Sep 21 02:30 code -rw-r--r-- 1 cesar staff 41K Sep 21 12:40 devel.html -rw-r--r--@ 1 cesar staff 87K Sep 18 11:59 e.pdf drwxr-xr-x 4 cesar staff 136B Sep 10 00:44 fig -rw-r--r-- 1 cesar staff 1.8K Sep 17 00:45 index.html
Then the following HTML will be generated:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"> <html> <head><title>Directory listing for "path/to/dir/"</title></head> <body> <h1>Directory listing for "path/to/dir/"</h1> <ul> <li><a href='path/to/dir/..'>..</a></li> <li><a href='path/to/dir/Makefile'>Makefile</a></li> <li><a href='path/to/dir/code'>code</a></li> <li><a href='path/to/dir/devel.html'>devel.html</a></li> <li><a href='path/to/dir/devel.rst'>devel.rst</a></li> <li><a href='path/to/dir/e.pdf'>e.pdf</a></li> <li><a href='path/to/dir/fig'>fig</a></li> <li><a href='path/to/dir/index.html'>index.html</a></li> </ul> </body> </html>
The client browser will render the above HTML code like this.
8.2.3 Implementation
Severs, after doing some initialization, usually enter an infinite loop where they
- wait for a request,
- compute something,
- reply to the client.
This loop is usually called the service loop. The service loop for mini-httpd will be as follows:
- Wait for a new client (system call accept(2)).
- fork(2) a new process, which will deal with the client (that is, it will execute the function serve, see attached code below). The main process shall close the client socket and the new process shall close the accepting socket.
- Read the HTTP request (function read_request).
- Parse it (function parse_request) and build a reply (build_response).
- Send the HTTP status code and headers (write_response_headers).
- Send the message body (functions write_response_body_dir and write_response_body_file).
- Call exit(3) from the client process.
- From the main process, periodically call the wait(2) system call to clear the queue of terminated children processes (use flag WNOHANG to avoid getting block waiting for children to finish).
If the main process receives the signal SIGUSR1, it will have to reload the configuration file, chdir(2) into a new directory and reopen the accepting socket. Use the following design:
- Make the signal handler to set a bit indicating that the signal has been received but the new configuration has not yet been applied.
- Some system calls (such as accept(2) ;) will return the error EINTR when a signal is received. Detect this condition and, if the bit is set, apply the new configuration and clear the bit.
Your server will write informational and debug messages to the standard output, using the following format:
mini-httpd: starting! mini-httpd: pid 2110 mini-httpd: argc 1 mini-httpd: (re-)loading configuration file... mini-httpd: done mini-httpd: port '8080' cwd '/home/cesar/httpd-root/' ...
8.2.4 Template code
Ver. 1: mini-httpd-20150921.tar.gz