Nous pouvons d'abord nous demander pourquoi la période s'étalant de la fin des années 60 à la fin des années 80 est si importante. A partir de 1988, l'ordinateur personnel (PC) conduit à un nouveau modèle d'informatique d'entreprise. L'architecture sous-jacente est une architecture de type client-serveur avec les grands systèmes (mainframes) et les mini-ordinateurs (minicomputers) comme serveurs frontaux (frontend), et qui sont les serveurs de données pour les machines de bureau comme les IBM PC. Pour faire communiquer le client avec le serveur nous avons besoin d'un réseau de communication. Or, à partir de la fin des années 60, des produits réseaux comme les modem, les LAN (Local Area Network) et les routeurs sont arrivés à maturité se sont mis en place afin de réaliser la communication entre les clients et le serveur. Ces trois produits sont des boites noires de l'économie digitale globale qui émerge à partir de la fin des années 80. On les classe souvent dans la catégorie des General purpose technologies. Ces trois technologies ont pu se développer à cause d'un élément politique majeur intervenu en 1968.
En effet, cette année là, aux États-Unis, la Commission fédérale des communications (FCC) a levé l'obstacle principal à l'apparition d'une structure de marché favorisant les communications de données. Pour cela, elle a autorisée la possibilité à n'importe quel dispositif de pouvoir s'accrocher aux lignes téléphoniques (monopole d'AT&T). De plus, les dispositifs autorisés n'étaient pas forcément produits par AT&T. L'idée était donc de rompre avec la situation de monopole d'AT&T afin qu'une compétition entre de nouveaux acteurs puissent se mettre en place. Évidemment, AT&T, fondée en 1885, a tout fait pour bloquer la décision.
Revenons maintenant aux faits marquants qui se sont déroulés de la fin de la guerre à la fin des années 60. Curieusement, à la fin de la seconde guerre mondiale, IBM dominait le marché des équipements de bureaux mais n'était pas un acteur en informatique. C'est en 1952 qu'IBM entre sur le marché de l'informatique. Voir à ce sujet le livre Father, Son & Co.: My Life at IBM and Beyond dont un des coauteurs est Thomas Watson. Sous sa présidence, dès la fin des années 60, IBM dominait l'industrie des mainframes, grâce notamment à sa participation à des projets nationaux financés largement par la Défense américaine et grâce aussi à l'architecture flexible et modulaire de la série d'ordinateurs IBM 360 et 370.
A partir de la fin de la deuxième guerre mondiale trois ruptures technologiques ont eu lieu successivement, de sorte qu'à la fin des années 60 l'industrie de, l'informatique était prête à franchir de nouveaux horizons. Il s'agit de l'apparition des :
Sur cette même période de l'après deuxième guerre mondiale nous avons vu l'arrivée de la notion de modem (pour modulation/démodulation) afin de faire transiter des données sur une ligne téléphonique et pas seulement de la voix. L'article suivant, daté de 1955, et intitulé Transmission of digital information over telephone circuits, publié au titre du Bell System Technical Journal, évoque la théorie des modems. Plusieurs entreprises ont affiné la technologie dont Bell qui a mis au point le modèle de modem 101 capable de transmettre à 110bps. Un exploit pour l'époque ! L'objectif était de transmettre le plus de 1 et de 0 sur une période de temps fixée. C'est ce premier modem commercial qui, en 1958, lance l'ère et la structuration du marché de la communication de données.
Rappelons qu'à cette époque, il a été aussi nécessaire de connecter les mainframes à des périphériques comme les imprimantes, d'où la nécessité des modems (en fait de leurs évolutions dans le monde du réseau local) pour transmettre l'information. Toujours à cette époque, les petits mainframes que l'on appelait les minicomputers parce que basés sur les transistors, ont eux aussi fonctionné sur le principe d'attachement de périphériques à une unité centrale. Les minicomputers étaient bien adaptés aux petites et moyennes entreprises si bien qu'un marché plus large que celui des mainframes a vu le jour. Le PDP-8 construit par DEC est un exemple emblématique de minicomputers.
Une des premières expériences documentées de connexion longue distance d'un ordinateur à un autre est l'article de Marill et Roberts intitulé Towards a cooperative network of time-sharing computers. Il est utile de lire cet article pour mesurer les difficultés de l'époque et les leçons qui ont pu en être tirées. Au passage, notons qu'il ne s'agit ici que de connecter entre eux seulement deux ordinateurs, pas un de plus !
Enfin, toujours avant la fin des années 60, est apparu la notion de temps partagé (Time Sharing) qui correspond au besoin suivant. A l'époque, les programmes sont crées sur des cartes perforées, puis passés à un opérateur qui le lance sur le mainframe. Ce mode de fonctionnement n'était pas satisfaisant aux yeux, notamment des programmeurs qui souhaitaient accéder directement à la machine, sans passer par un intermédiaire. Donc, pour court-circuiter l'opérateur on a inventé le temps partagé permettant à un ordinateur d'exécuter simultanément, en fait par tranche de temps, plusieurs programmes. Le temps partagé nécessite de nouveaux logiciels et de nouveaux matériels, et l'innovation la plus marquante de l'époque est l'apparition de la notion de Système d'exploitation (OS) qui donne l'illusion que plusieurs personnes accèdent à l'ordinateur central simultanément. Enfin, nous pouvons dire que le temps partagé s'oppose à l'informatique par lots (batch computing). Par lots nous entendons ici les lots de cartes perforées que l'opérateur présente à un mainframe.
La Table 1 liste des entreprises, des lignes de produits et les technologies associées en matière de Data Communications. Les technologies de communication des modems sont :
| Company | Year founded | 300bps modems | 300-4,800bps modems | >4,800bps modems | FDM | TDM | Comm. Proc. |
|---|---|---|---|---|---|---|---|
| AT&T | 1880 |
x | x | ||||
| IBM | 1911 | x | x | x | |||
| Milgo | 1955 | x | x | ||||
| Codex | 1962 | x | x | x | |||
| ADS | 1968 | x | x | x | x | x | x |
| Infotron | 1968 | ||||||
| GDC | 1969 | x | x | x | x | ||
| Paradyne | 1969 | x | |||||
| Timeplex | 1969 | x | |||||
| UDS | 1969 | x | x | ||||
| Vadic | 1969 | x | x | x | |||
| Intertel | 1970 | x | x |
Au moment des toutes premières expériences de connexion d'ordinateurs à ordinateurs (voir plus haut par exemple l'article de Marill et Roberts), les scientifiques ont compris que le médium de communication (le réseau téléphonique) posait problème. En effet, il était centralisé ce qui veut dire qu'il y a nécessairement un point central par lequel passe tout le trafic. Or, si ce point central est défaillant, plus personne ne peut communiqué avec personne.
Paul Baran, proposa dès 1962 l'étude intitulée On distributed Communications Networks dont le résumé est :
A discussion of the problem of building digital communication networks using links with less than perfect reliability. The redundancy level used is defined as a measure of connectivity. The systems planner must choose that form of redundancy so that the form of the noise or interference appears to be somewhat statistically independent for each redundant element added. If this goal is completely met, there can be an exponential payoff for a linear increase of added elements. As an example, the paper examines the synthesis of a system in which the form of the disturbance or noise is the simultaneous destruction of many geographically separated installations. The system considered is a high-speed digital data transmission network composed of unreliable links, but which exhibits any arbitrarily desired level of systems reliability or survivability.
Il est impératif ici de faire une pose pour lire, comprendre et analyser les éléments de Baran. A vous de prendre le temps nécessaire pour remplir ces tâches. Il faut aussi comprendre qu'en 1962 l'article évoque des idées et pas encore des implémentations.
En 1965, Donald Davies poursuivit dans la direction des idées de Baran et proposa un article intitulé Remote On-line Data Processing and its Communication Needs. Là aussi, nous avons l'arrière plan des idées essentielles qui serviront plus tard à concevoir Internet. L'apport décisif de Davies est d'avoir introduit pour la première fois le terme de "packet switching".
Dans la lignée de la discussion précédente, nous discutons maintenant de méthodes de communication importantes permettant l'échange d'information entre plusieurs entités.
Le service Circuit Switching est un service orienté connexion. Il fournit un chemin dédié de l’expéditeur au destinataire. Pour la commutation en circuit une configuration de connexion est nécessaire pour envoyer et recevoir des données. Il y a très peu de risques de perte de données et d'erreurs dues au circuit dédié, mais une grande partie de la bande passante est gaspillée car le même chemin ne peut pas être utilisé par d'autres expéditeurs en cas de congestion. La commutation des circuits est complètement transparente ; l'expéditeur et le destinataire peuvent utiliser n'importe quel format de débit binaire ou méthode de tramage.
La commutation de paquets est un service sans connexion. Il ne nécessite aucun chemin dédié entre l’expéditeur et le destinataire. Il impose une limite supérieure à la taille des blocs. Dans la commutation de paquets, la bande passante est utilisée librement car des sources indépendantes peuvent être utilisées dans n'importe quel chemin. Il y a plus de risques de perte de données et d'erreurs ; les paquets peuvent arriver dans le mauvais ordre.
Lire la première moitié de la page Wikipedia sur les modems, puis ce texte à partir de la page 96, et explicitez les différences entre bandwidth, baud, symbol, et bit rate.
Le système de sémaphore prussien (dt. Preußischeroptischer Telegraf) était un système de communication télégraphique utilisé entre Berlin et Coblence dans la province du Rhin et était en service de 1832 à 1849. Les messages officiels et militaires étaient transmis par signaux optiques sur une distance de près de 550 km via 62 stations télégraphiques. Chaque station était équipée de 6 bras télégraphiques comportant chacun 4 positions pour le codage.
Une image a une taille de 1 920 x 1 080 pixels (Full HD) avec de vraies couleurs, ce qui signifie que 3 octets par pixel sont utilisés pour les informations de couleur.
Le protocole de liaison de données RNIS utilise une méthode de signalisation appelée 2B1Q, où la tension est définie selon le tableau suivant. Codez la séquence de bits 1011011011 en utilisant 2B1Q.
| Dibit | Signal level |
|---|---|
| 10 | +450 mV |
| 11 | +150 mV |
| 01 | −150 mV |
| 00 | −450 mV |
Note : Pour des compléments d'information et une vue générale des problèmes, vous pouvez consulter Principles of Digital Communication qui est un ouvrage du MIT.
Note : D'autres ressources générales se trouvent sur la page suivante intitulée Computer Networking: Related Online Links.
Considérons un réseau à commutation de circuits. Le temps d'établissement du circuit est de S secondes, le délai de propagation est de d secondes par saut et le débit de données est de b bps. Quel est le délai d'envoi d'un message de x bits sur un chemin k-hop ?
Considérons un réseau à commutation de paquets. Le temps d'établissement du circuit est de s secondes, le délai de propagation est de d secondes par saut, la taille du paquet est de p bits et le débit de données est de b bps. En supposant que tous les paquets suivent le même chemin k-hop, quel est alors le délai d'envoi d'un message de x bits en termes de paquets ?
Imaginez que la NASA envoie un vaisseau spatial sur la planète Mars, qui y atterrit. Une liaison point à point de 128 kbps (kilobit par seconde) est établie entre la planète Terre et le vaisseau spatial. La distance entre la Terre et Mars fluctue entre env. 55 000 000 km et environ 400 000 000 km. Pour d'éventuels calculs ultérieurs, nous utilisons les 55 000 000 km, qui est la distance de la Terre à Mars, lorsqu'ils sont les plus proches l'un de l'autre. La vitesse de propagation du signal est de 299 792 458 m/s, ce qui correspond à la vitesse de la lumière.
Nota : Déviation entre les puissances de 1024 (base 2) et les puissances de 1000 (base 10). Les informaticiens aiment utiliser les puissance de 2. Ainsi on trouve les Mégabyte (MB) du système international vs Mébibyte (MiB) du système des informaticiens. Exemple : un mebibyte = 1 MiB = B = 1 048 576 B ; avec la définition que un byte = un octect = 1 B = 8 bits.
Deux hôtes sont connectés via un commutateur de paquets avec des liaisons à 107 bits par seconde. Chaque lien a un délai de propagation de 20 microsecondes. Le commutateur commence à transférer un paquet 35 microsecondes après sa réception. Si 10 000 bits de données doivent être transmis entre les deux hôtes en utilisant une taille de paquet de 5 000 bits, le temps écoulé entre la transmission du premier bit de données et la réception du dernier bit de données en microsecondes est de :
Construire un glossaire de tous les concepts présents dans l'article On distributed Communications Networks de Paul Baran. Un glossaire est un dictionnaire où, à chaque concept est associée une définition.
Deux canaux de 64 kbit/s chacun et un canal de 640 kbit/s sont multiplexés en utilisant le multiplexage temporel (TDM). Si l’entrelacement est fait au niveau d’un octet (8 bit), déterminer :
Un système de multiplexage TDM est caractérisé par une trame de 10 Time Slots ; dans chaque time slot, 128 bits sont transmis. Le système est utilisé pour multiplexer 10 canaux téléphoniques numériques, chacun desquels a une vitesse de 64 kbit/s.
Calculer la vitesse de transmission du multiplexeur et la durée de la trame
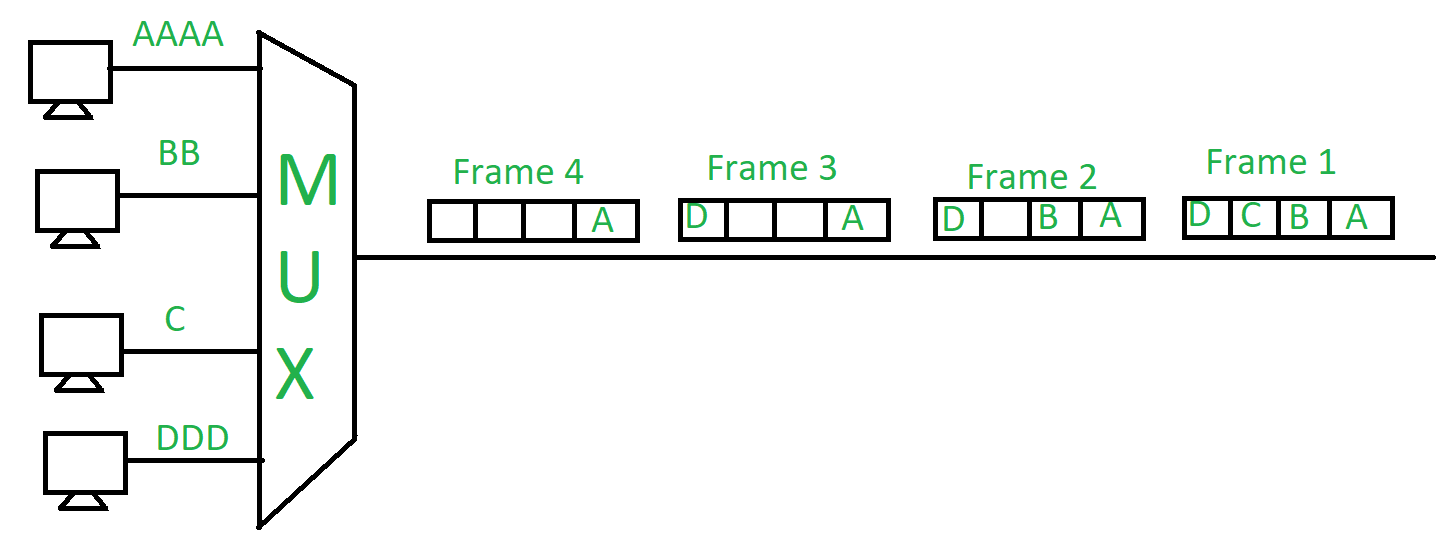
Quelle est la méthode de multiplexage qui est utilisée dans l'exemple de la Figure 1 ? TDM, FDM ? Multiplexage statistique ?
Dessiner les échanges d'information entre la source et la destination pour les autres méthodes que celle employée ci-dessus à la Figure 1, tout en gardant les mêmes données à transmettre.
Le décennie des années 60 est riche en évènements majeurs. À partir de 1962, J.C.R. Licklider rédige des notes sur son concept de réseau intergalactique, où tout le monde sur la planète est interconnecté et peut accéder aux programmes et aux données sur n'importe quel site et depuis n'importe où. Il s’entretient avec son propre « réseau intergalactique » de chercheurs à travers le pays. En octobre, « Lick » devient le premier responsable du programme de recherche informatique de l’ARPA, qu’il appelle l’Office des techniques de traitement de l’information (IPTO).
En 1966 Robert Taylor succéda à Sutherland comme directeur de l'IPTO et pris conscience de l'importance grandissante du temps partagé. Il décida de construire une communauté scientifique ARPA autour de la notion. Au bas de la page 10 de la référence, on peut lire :
In February of 1966 I went in to see the head of ARPA, Charles Herzfeld, and said I’d like to build a network that would connect these timesharing systems that Lick had set up in various places around the country. And Herzfeld, who kept up with what Lick had been doing and what Ivan had been doing and what I had inherited, understood right away what I was talking about and he took a million dollars out of one of his other programs and he put it in my program and we were off and running on the ARPANET.
Au début de 1967, l'ARPA a organisé une réunion de chercheurs à l'Université du Michigan à laquelle Wes Clark a été invité. L'un des points centraux de cette réunion était la question de savoir comment connecter entre eux différents types de grands ordinateurs centraux exécutant des systèmes d'exploitation disparates. Larry Roberts, qui avait rejoint l'IPTO en tant que directeur de programme relevant de Robert Taylor, était favorable à l'installation d'un ordinateur central au centre du pays auquel tous les ordinateurs seraient connectés. Cette solution en étoile (Star network) n’était pas une solution parfaite, mais cela résolvait raisonnablement le problème de la connexion de chaque ordinateur à tous les autres ordinateurs. En effet, si l'on veut que chaque ordinateur, parmi , puisse parler directement à tous les autres il nous faut liens de communications, ce qui est prohibitif quand devient grand.
À la fin de la réunion, Clark a eu l’idée d’une solution différente au problème. Lors d'un retour en voiture à l'aéroport après la réunion, Clark a suggéré à Roberts, Taylor et Dave Evans l'idée de connecter des ordinateurs plus petits ensemble pour former le réseau et de connecter les ordinateurs plus gros à ces nœuds plus petits. Après son retour à Washington D.C., Roberts comprit rapidement le mérite de la suggestion de Clark et c’est ainsi qu’est née la topologie de Arpanet. Les petits ordinateurs sont devenus connus sous le nom d'IMPs, les processeurs de messages d'interface.
En bref, l'Interface Message Processor (IMP) était le nœud de commutation de paquets utilisé pour interconnecter les réseaux participants à l'ARPANET de la fin des années 1960 à 1989. Il s'agissait de la première génération de passerelles, connues aujourd'hui sous le nom de routeurs. Le logiciel IMP et le protocole de communication réseau ARPA fonctionnant sur les IMP ont été discutés dans la RFC 1 qui est le premier document d'une série de documents de normalisation publiés par ce qui deviendra plus tard l'Internet Engineering Task Force (IETF). Cette RFC 1 est à lire et à comprendre !
La RFC 1 s'appuie sur des travaux effectués au NPL (National Physical Laboratory) de Londres par Davies. Il est l'un des premiers à utiliser la transmission par datagramme (commutation de paquet), des routeurs, et des liaisons à haut débit. Techniquement, le réseau du NPL est l'égal du réseau Arpanet, mais il ne connait pas le même développement. Le directeur des services informatique de l'ARPA, Larry Roberts, intègre les concepts de routeur et de datagramme dans la conception de l'Arpanet. Comme le réseau du NPL fonctionne à la vitesse de 768 kbit/s, la vitesse prévue pour l'Arpanet passe de 2,4 kbit/s à 50 kbit/s et un format de paquet similaire est adopté.
Si Paul Baran est le premier à avoir théorisé les datagrammes en 1964, il revient à Davies d'avoir opérationnalisé le concept dès 1965. Il revient à Davies également d'avoir utilisé le terme de "packet" (datagramme en français), qu'il choisit avec l'aide d'un linguiste du NPL dans le but d'être traduit dans toutes les langues sans difficulté.
Lawrence Roberts, dans l'article The arpanet and computer networks reconnait l'apport indéniable des travaux entrepris au NPL :
Also presented at the Gatlinburg Symposium was Donald Davies's first open publication on the NPL packet network concepts presented by Roger Scantlebury, "A Digital Communication Network for Computers Giving Rapid Response at Remote Terminals." It detailed the concept of a high level packet net with high capacity nodal switches and interface computers in front of mainframe computers. This was the first time that either Davies or I knew anything about the work of each other since our 1965 contact. The NPL paper clearly impacted the ARPANET in several ways. The name "packet" was adopted, much higher speed was selected (50 Kilobit/sec vs. 2.4 Kilobit/sec) for internode lines to reduce delay and generally the NPL analysis helped confirm the concept of packet switching.
Le réseau NPL est connecté avec d'autres réseaux, en particulier Arpanet en 1973 grâce aux travaux du groupe de recherche de Peter Kirstein de l'University College de Londres. Il est également connecté en 1976 au réseau français Cyclades grâce au Réseau informatique européen (European Informatics Network) et fonctionne selon le principe des datagrammes.
Mais, le réseau Cyclades n'imposant pas de contrôle de flux aux sources de données, il est accepté que des destructions de paquets dans le réseau puissent être inévitables, et même systématiques si certaines sources de paquets sont trop rapides pour les destinations qu'elles visent : le service est dit best effor . Nous pouvons dire que Cyclades était un réseau sans QoS (Quality of Service).
On notera également une mention à Cyclades dans l'article The arpanet and computer networks de Lawrence Roberts. C'est un hommage aux travaux des français ! Toujours dans cet article, dans le même paragraphe parlant de Cyclades, nous noterons également la remarque fondamentale suivante :
The ARPANET also operates using datagrams but perhaps the most avid supporter of the concept is the designer of CYCLADES, Louis Pouzin. As with any datagram network, a large part of the communications funtions must be implemented in the host computers; the packet ordering, message formation, flow control, and virtual connections support.
Un autre choix possible serait de mettre toute l'intelligence ou une partie de l'intelligence dans les IMPs, à partir du moment ou on accepte les IMPs. Il convenait à l'époque de trouver les bons compromis. C'est une question centrale quand on veut assurer de la QoS. C'est peut-être cette question centrale qui n'a pas été suffisamment creusée par les personnes de Cyclades (?).
Un datagramme est une unité de transfert de base associée à un réseau à commutation de paquets. Les datagrammes sont généralement structurés en sections d'entête (header) et de charge utile (payload). Les datagrammes fournissent un service de communication sans connexion sur un réseau à commutation de paquets. La livraison, l'heure d'arrivée et l'ordre d'arrivée des datagrammes n'ont pas besoin d'être garantis par le réseau.
Faites un résumé de la RFC 768 avec des exemples concrets de datagrammes. Écrivez ensuite un programme (dans le langage de votre choix) qui émet des datagrammes et un autre programme qui les décode.
Aide. En BASH on peut imaginer un script qui écrit un datagramme dans un fichier et un autre script qui lit le fichier. Exemple d'écriture : echo "mon datagramme" | tee -a /chez_moi/fichier.log.
Reprendre l'exercice précédent afin de programmer l'émission d'un datagramme et sa réception par plusieurs noeuds dans le cadre d'un réseau en étoile comme celui présenté à la Figure 2. Il faudra donc un programme qui publie en direction du HUB, un programme HUB qui va diffuser le datagramme auprès des autres participants, et des programmes qui réceptionnent le datagramme émis et le décode.

Nous supposons maintenant que la topologie réseau est un bus. Reprogrammez l'exemple précédent où un datagramme doit être envoyé et décodé par N hôtes, en utilisant le mécanisme du Multicast et plus particulièrement les utilitaires msend, mreceive. Il conviendra d'abord de compiler les codes sources de ces utilitaires. L'idée ici est d'encapsuler un datagramme dans un service générique de diffusion simultanée.
Aide : Installer msend et mreceive
depuis ce
site. Remplacer mreceive.c par
Récupérer ce script qui est un script Bash qui génère une trame respectant la RFC 768 et l'envoie sur l'adresse de braodcast. Vous devez écrire un script qui va effectuer le décodage de la trame et afficher chacun des champs. Pour faire la simulation, ouvrir 3 fenêtres sur la même machine (on fait du broadcast entre moi et moi si vous préférez) :
Attention : pendant que le script de décodage dort (sleep 5), il peut y avoir plusieurs émissions de messages par msend. Dans ce cas, il faut gérer toutes les lignes du fichier test.txt qui n'ont pas été encore décodées et pas seulement la dernière ligne. Nous sommes ici en présence d'un problème de synchronisation entre un processus qui écrit et un processus qui lit.
Un peu dans le même ordre d'idée que précédemment vous pouvez reprogrammer la solution au problème de diffusion d'un datagramme à plusieurs hôtes en utilisant le protocole Zeroconf. Veuillez d'abord lire la documentation puis réaliser les implémentations en Python avec le module dédié. Vous devez très certainement installer le module Python via une commande pip. Vous pouvez également vous documenter en lisant la page Wikipedia consacrée à Zeroconf et tout particulièrement le paragraphe Security issues, puis répondre à la question suivante : est-ce que ce protocole est adapté à l'échelle de la planète ?
À partir de janvier 1969 les efforts pour construire ARPANET se sont amplifiés, en partant d'IMPs réalisant l'interconnexion de lignes téléphoniques d'AT&T et les ordinateurs en bout de réseau, dits les "hosts". Le couple IMP et ligne téléphonique est appelé à l'époque un sous-réseau (subnet).
Les hosts doivent communiquer avec les hosts en envoyant des messages dans le subnet. Les IMPs routent les messages en commençant par les découpant en 8 paquets (max) et chaque paquet a une taille de 1000 bits (max). L'IMP destination rassemble les paquets pour reconstituer le message.
L'architecture étant maintenant fixée, il a été nécessaire de spécifier le routage des paquets. À l'époque on ne parlait d'ailleurs pas de protocole et le routage devait être fiable et sans erreur.
À l'époque, Robert Kahn faisait également partie de l'équipe BBN qui a développé l'Interface Message Processor (IMP), un petit ordinateur qui servait de commutateur de paquets ARPANET et qui standardisait l'interface réseau avec tous les ordinateurs hôtes connectés.
L'interview
de Robert
Kahn par Vinton Cerf nous donne notamment une idée de l'impact des
principaux acteurs sur le monde d'aujourd'hui :
Cerf: This actually leads to a related kind of question. Looking
back now, although we have not covered all aspects of your career
and we are going to do that, as much as we can anyway. If you
look back on all the various things that you’ve done, what sort of
impacts do you see as a consequence of the work that you’ve done?
How would you characterize the results of the research, or the
results of the projects, or the results of the ideas, if you were
to look back now over this 30 to 40 year period? What kind of
impact do you see has happened?
Kahn: Well, clearly the thing that’s gotten the biggest play in
the outside world has been the Internet, which I guess was
something that nobody could have predicted would have evolved
exactly as it did. You know as well as anybody that this is not a
thing that a single person did, or that occurred without the help
of a lot of people over a lot of time. In fact, it really wasn’t
until the infusion of a lot of the corporate funds into pushing it
out that it really began a global and worldwide thing. Plus the
backing of governments around the world, because it wouldn’t have
happened if both of those hadn’t happened. It might have been an
interesting research project. I still think we’re a long away
from learning what the final impact of the Internet is. Networks
are changing. New networks are coming up. People are constantly
trying to reinvent networks. They’re constantly trying to say,
“Well, the old ones don’t work. We need new ones.” And yet,
there are some things that are pretty constant in all of this as
things go forward - the need for connectivity, the need for
bandwidth, the need for reliability. I was struck, in a movie
that I had put together for the unveiling of the ARPANET, to
listen to all of the computer folks talk about what that was
about. They all talked about it in terms of the technology of the
time - the need for the powerful graphics simulator to connect to
a remote time-sharing system. It was all in terms of what was
there at the moment. Whereas when you listened to the
communication folks, they would talk about the need for reliable
communication. They would talk in things that didn’t… They
wouldn’t say, “We need faster light emitting diodes to move it
twice the bandwidth.” I think we’re now getting to the point
where people are actually talking more in terms of the generics.
So: the Internet is about connectivity. The Internet is about
access to information. The Internet is about reliability. Those
will probably be true ten years from now, 100 years from now, to
the extent that that kind of capability exists.
Nota : lire également l'interview de Vint Cerf, un autre père fondateur de l'Internet.
Nota : en décembre 1970, le Network Working Group (NWG) dirigé par Steven Crocker termina le protocol initial Host-to-Host d'ARPANET, appelé le Network Control Protocol (NCP). Lire l'interview de Crocker ici. Dans le protocol NCP on trouve l'idée qu'un ordinateur a la responsabilité d'assurer le "log-in", par exemple pour assurer l'authentification, avant de donner accès à l'utilisateur au système.
Après avoir lu la page Wikipedia consacrée à l'algorithme de Dijkstra, développer tous les calculs qui sont faits pour déterminer le plus court chemin entre les sites a et b de l'exemple du haut de page.
Après avoir lu la page Wikipedia consacrée à l'algorithme de Bellman-Ford-Moore, développer tous les calculs qui sont faits pour déterminer le plus court chemin entre s et chaque autre sommet du graphe de l'exemple du haut de page.
Appliquer l'algorithme de Bellman, Ford et Moore à l'exemple donné sur la page Wikipedia de l'algorithme de Dijkstra, et appliquer l'algorithme de Dijkstra sur l'exemple de la page Wikipedia de l'algorithme de Bellman, Ford et Moore. Attention, il va peut-être falloir faire des hypothèses supplémentaires car certaines informations nécessaires aux déroulés des algorithmes sont manquantes (?). Veuillez expliciter ces hypothèses.
La couche Réseau contient les algorithmes de routage qui peuvent être regroupés en deux catégories : les non-adaptatifs et les adaptatifs. Les algorithmes non adaptatifs ne fondent pas leurs décisions sur la mesure ou l'estimation du trafic et de la topologie en temps réél. Au contraire, le choix de la route à prendre est calculé par avance, et mis en place sur tous les IMP quand le réseau est initialisé. Cette procédure est parfois appelée routage statique.
À l'inverse, les algorithmes adaptatifs modifient leurs décisions de routage pour traduire les variations de toologie et de trafic réél. Il existe trois familles d'algorithmes adaptatifs qui diffèrent par la manière dont ils utilisent les données. Les algorithmes globux utilisent les informations collectées dans l'ensemble du sous-réseau pour prendre les meilleures décisions. Cette approche est appelée routage centralisé. Les algorithmes locaux s'exécutent sur chaque IMP et n'utilisent que les informations disponibles, telles que les longeurs des files d'attente. Enfin, la troisième famille d'algorithmes utilise un mélange d'informations locales et globales. Ils sont appelés algorithmes distribués.
Dans quelle famille rangez-vous les précédents algorithmes de routage (l'algorithme de Dijkstra et l'algorithme de Bellman, Ford et Moore) ?
Le document en ligne suivant classe les algorithmes de routage en deux catégories appelés algorithmes centralisés et algorithmes distribués. Après avoir lu ce document, veuillez expliquer les liens entre ces formulations et les formulations d'algorithmes adaptatifs et non-adaptatifs tels qu'ils sont présentés ci-dessus. L'objectif de l'exercice est de clarifier les notions, en cherchant les éléments communs de vocabulaire. Quels sont les principes généraux qu'il faut retenir ?
Dans le document en ligne suivant, deux méthodes de routage ne sont pas accompagnées d'exemples. L'objectif de cet exercice est de construire des exemples pour ces méthodes, permettant de mieux comprendre les étapes des algorithmes. Vous pouvez mimer la présentation des illustrations déjà présentes dans le document.