Le polycopié du module est disponible ici.
Pour tester du code Redis en ligne voir le lien https://onecompiler.com/redis
Pour tester du code MongoDB en ligne voir le lien https://onecompiler.com/mongodb
Attention, ces interpréteurs en ligne ne vous permettent pas d'interagir avec des fichiers qui seraient déposés sur votre propre disque dur.
Nous avons vu que l'image Ubuntu que je vous ai distribuée ne pouvait pas être lue avec VirtualBox installé dans les salles du CRiT. Maintenant, essayons tout de même avec le VirtualBox du CRiT, mais sur une distribution Linux « ultra légère » qui tourne complètement en mémoire RAM (pas de disque). Pour cela, veuillez télécharger, depuis votre poste du CRiT, l'image Alpine Linux (instance Virtual, x86_64) depuis https://www.alpinelinux.org/downloads/. Ensuite, demandez à VirtualBox de l'ingérer (procédure que j'ai déjà détaillée en cours), puis démarrez l'instance. Le login est root et il n'y a pas de mot de passe. Vous allez vous retrouver sous le prompt #. La suite de la configuration est la suivante :
Lancer la commande suivante pour configurer le clavier :
setup-keymap, choisir fr puis fr-azerty
Lancer ensuite la commande suivante vous permettant de
configurer votre distribution Alpine Linux : setup-alpine
Veuillez choisir les paramètres par défaut, sauf, si vous voulez
ajouter un utilisateur supplémentaire.
Le gestionnaire de paquets, sous Alpine, est apk (Alpine Linux
package keeper (manager)). Veuillez lancer les commandes
suivantes pour installer redis, python, nano :
apk add python3 nano redis
Taper ensuite les deux commandes suivantes pour activer le
gestionnaire de paquets propre à Python, qui s'appelle pip ou
pip3. Pour cela on se place dans un environnement virtuel :
python3 -m venv tutorial-env
source tutorial-env/bin/activate
Vous pouvez maintenant installer la librairie Python redis pour
dialoguer en Python avec le serveur Redis : pip install redis
Lancer le serveur redis : redis-server & (n'oubliez pas
l’esperluette pour reprendre la main en ligne de commande)
Vous pouvez maintenant tester que Redis est fonctionnel. Il faut
éditer, avec nano, le programme suivant :
import redis
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
r.set('foo', 'bar')
# True
print(r.get('foo'))
# bar
Vous pouvez lancer ce programme test.py par la commande :
python3 test.py et vous devriez obtenir l'affichage de bar.
Attention : si vous installer Alpine Linux chez vous, il ne
faudra jamais éteindre complètement l'instance Alpine. En effet,
comme elle tourne en mémoire RAM, une extinction complète vous
fera perdre toutes les installations effectuées dans
l'instance. Il faut donc la mettre en sommeil. VitualBox sait
faire cela sans problème. A l'IUT, pour l'instant, comme il n'y
a pas de persistance de vos données, c'est foutu ! Il faudra
recommencer l'installation à chaque fois !
Compilation de Redis à partir des sources : les sources écrits en C de Redis sont disponibles sur le site principal de Redis. Vous pouvez donc les recompiler. Il vous faut un compilateur C (principalement).
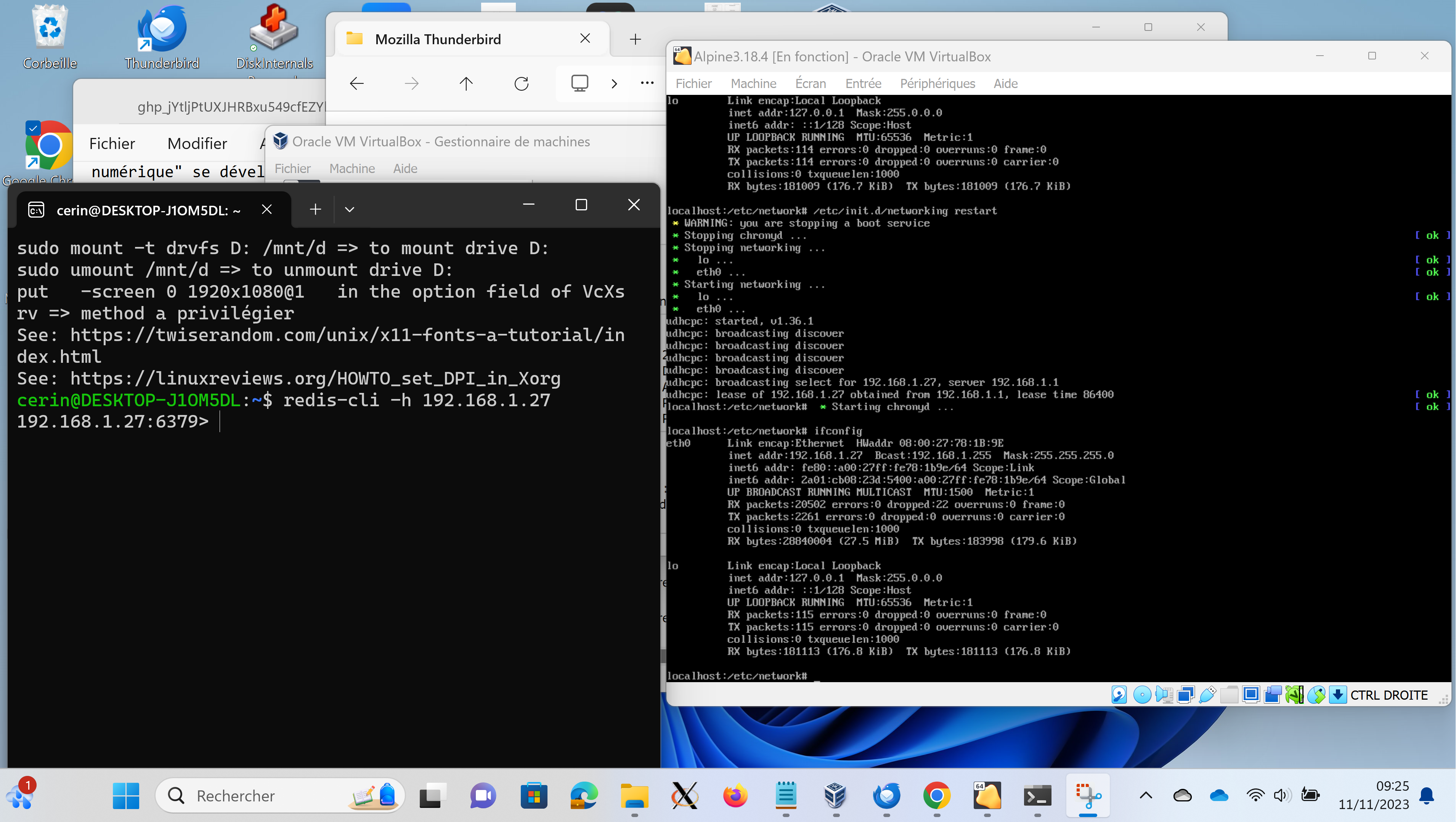
Si vous souhaitez développer en dehors de la VM Alpine Linux, par exemple parce que vos outils de développement préférés (éditeur, IDE...) sont en dehors de la VM Alpine Linux, il vous faut exposer le serveur Redis en dehors de la VM Alpine Linux. En effet, celui-ci est par défaut dans un sous réseau local dans la plage d'adresses 10.x.x.x alors que sur les machines du CRIT, ou chez-vous, le réseau par défaut est dans la plage 192.168.x.x. Pour que votre VM Alpine prenne automatiquement une adresse dans cette dernière plage d'adresses, le plus simple est de configurer, dans VirtualBox, le réseau de votre VM Alpine en mode pont (bridge) plutôt qu'en NAT. Ensuite, dans la VM Alpine Linux, vous relancez le système pour renouveler l'adresse IP de la VM Alpine via la commande /etc/init.d/networking restart. Dans la Figure 1 qui suit, vous pouvez observer que :
Cependant, il reste une manipulation à faire du côté de l'image Alpine Linux car je ne peux pas me connecter au serveur redis depuis la machine vituelle Ubuntu :
cerin@DESKTOP-J1OM5DL:~$ !redis redis-cli -h 192.168.1.27 192.168.1.27:6379> set foo bar (error) DENIED Redis is running in protected mode because protected mode is enabled and no password is set for the default user. In this mode connections are only accepted from the loopback interface. If you want to connect from external computers to Redis you may adopt one of the following solutions: 1) Just disable protected mode sending the command 'CONFIG SET protected-mode no' from the loopback interface by connecting to Redis from the same host the server is running, however MAKE SURE Redis is not publicly accessible from internet if you do so. Use CONFIG REWRITE to make this change permanent. 2) Alternatively you can just disable the protected mode by editing the Redis configuration file, and setting the protected mode option to 'no', and then restarting the server. 3) If you started the server manually just for testing, restart it with the '--protected-mode no' option. 4) Setup a an authentication password for the default user. NOTE: You only need to do one of the above things in order for the server to start accepting connections from the outside. # Ici je suis allé exécuter la commande : CONFIG SET protected-mode no # dans la CLI de redis et dans l'image Alpine. Ensuite je peux reprendre # un test comme suit : 192.168.1.27:6379> set foo bar OK 192.168.1.27:6379>
Considérer le code my_json.py suivant, qui travaille sur le fichier csv suivant, et faites un commentaire des deux choix d'implémentation qui ont été faits afin de convertir un csv en json. Quel est l'avantage de l'une des représentations par rapport à l'autre ?
Contrairement à l'exemple précédent, vous pouvez utiliser la librairie Python Panda et en particulier les fonctions read_csv mais aussi to_json et merge, ceci afin de réaliser la dénormalisation et la sérialization en json. Lisez bien la page sur merge, qui contient aussi de l'information sur la jointure et la concaténation de tables.
Vous voyez donc qu'il y a plusieurs interfaces (librairies) que vous pouvez utiliser pour manipuler des fichiers csv. C'est à vous de mesurer quelle est l'interface qui convient le mieux à votre problème !
Le code my_json_jointure.py est construit sur la base de l'encodage CSV vers JSON vu précédemment à travers le code my_json.py. Le code implémente la jointure de deux représentations JSON sur l'attribut implicite commun 'Prénom Nom'. Vous pouvez chercher à implémenter la jointure pour l'autre représentation JSON. Les CSV utilisés par le code sont test.csv et test1.csv.
Le code reservations.py effectue une jointure entre deux dictionnaires et sur l'attribut att. L'opération travaille selon la méthode des deux boucles imbriquées. On avait convenu que l’on stockerait des JSON dans le serveur Redis, il convient de convertir les JSON en dict() pour pouvoir appeler l’opération de jointure du code. De même, une fois que la dictionnaire correspondant à la jointure a été généré, il faut le convertir en JSON et le stocker dans le serveur Redis.
Note : dans l’exemple numérique qui a été programmé, les deux ‘tables’ ont les mêmes noms d’attributs. Pour générer le résultat il faudrait programmer une ‘union’ des attributs. C’est à faire.
Si le module des Bloom filters n'est pas disponible avec votre installation de Redis, veuillez suivre complètement l'installation qui vous est proposée sur cette page. Vous devriez ensuite pouvoir terter comme cela est fait ci-après, sans oublier de relancer le serveur comme indiqué :
cerin@DESKTOP-J1OM5DL:~/Redis/RedisBloom$ killall redis-server
4136:signal-handler (1700405390) Received SIGTERM scheduling shutdown...
cerin@DESKTOP-J1OM5DL:~/Redis/RedisBloom$ 4136:M 19 Nov 2023 15:49:50.833 # User requested shutdown...
4136:M 19 Nov 2023 15:49:50.834 * Saving the final RDB snapshot before exiting.
4136:M 19 Nov 2023 15:49:50.842 * DB saved on disk
4136:M 19 Nov 2023 15:49:50.842 # Redis is now ready to exit, bye bye...
cerin@DESKTOP-J1OM5DL:~/Redis/RedisBloom$ redis-server /etc/redis/redis.conf
4149:C 19 Nov 2023 15:50:13.194 # Fatal error, can't open config file '/etc/redis/redis.conf': Permission denied
cerin@DESKTOP-J1OM5DL:~/Redis/RedisBloom$ sudo redis-server /etc/redis/redis.conf
cerin@DESKTOP-J1OM5DL:~/Redis/RedisBloom$ python
Python 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import redis
>>> r = redis.Redis()
>>> r.bf().create("bloom", 0.01, 1000)
True
>>> r.bf().add("bloom", "foo")
1
>>>
En ligne de commande, le programme précédent en Python devient :
cerin@DESKTOP-J1OM5DL:~/Redis/RedisBloom$ redis-cli bf.reserve bloom 0.01 1000
(error) ERR item exists
cerin@DESKTOP-J1OM5DL:~/Redis/RedisBloom$ redis-cli bf.info bloom
1) Capacity
2) (integer) 1000
3) Size
4) (integer) 1480
5) Number of filters
6) (integer) 1
7) Number of items inserted
8) (integer) 1
9) Expansion rate
10) (integer) 2
cerin@DESKTOP-J1OM5DL:~/Redis/RedisBloom$ redis-cli del bloom
(integer) 1
cerin@DESKTOP-J1OM5DL:~/Redis/RedisBloom$ redis-cli bf.reserve bloom 0.01 1000
OK
cerin@DESKTOP-J1OM5DL:~/Redis/RedisBloom$ redis-cli bf.add bloom foo
(integer) 1
cerin@DESKTOP-J1OM5DL:~/Redis/RedisBloom$
cerin@DESKTOP-J1OM5DL:~/Redis/RedisBloom$ redis-cli bf.exists bloom foo
(integer) 1
cerin@DESKTOP-J1OM5DL:~/Redis/RedisBloom$ redis-cli bf.exists bloom fooooo
(integer) 0
cerin@DESKTOP-J1OM5DL:~/Redis/RedisBloom$
Nous pouvons maintenant mettre en place un programme qui calcule le temps nécessaire pour insérer dans un bloom filter n éléments. Nous récupérons un dictionnaire de mots via la commande curl http://rali.iro.umontreal.ca/DEM//DEM-1_1.csv > DEMO.csv (le dictionnaire de mots est au format CSV et les mots sont dans la première colonne), puis nous lisons et insérons les mots dans un filtre de Bloom. Enfin nous calculons le temps nécessaire à l'exécution. Le programme est my_bloom.py. Son exécution donne, sur ma machine, le résultat suivant :
cerin@DESKTOP-J1OM5DL:~$ python my_bloom.py
Start to create the bloom filter over 140000 inputs
CPU Execution time: 5.34375 seconds
We found 15898 duplicates in the input
Wall time (also known as clock time or wall-clock time) is simply the total time
elapsed during the measurement. It’s the time you can measure with a stopwatch.
It is the difference between the time at which a program finished its execution and
the time at which the program started. It also includes waiting time for resources.
CPU Time, on the other hand, refers to the time the CPU was busy processing
the program’s instructions. The time spent waiting for other task to complete
(like I/O operations) is not included in the CPU time. It does not include
the waiting time for resources.
Quel est le temps d'exécution sur votre machine ? Faites varier le paramètre n et observer l'évolution du temps de calcul. Cette évolution suit-elle une loi linéaire en fonction de n ? quadratique en n ? exponentielle ?
Nous pouvons maintenant chercher à comparer les performances du type filtre de Bloom vis à vis du type ensemble (SET). Pour cela, nous reprenons le code précédent et nous remplaçons les opérations de gestion par un type filtre de Bloom par des opérations de gestion via un type ensemble (SET). Au final, le code est my_set.py. Quand on l'exécute, on obtient de meilleures performances en temps qu'avec un filtre de Bloom. À votre avis, pour quelles raisons ? :
cerin@DESKTOP-J1OM5DL:~$ python my_set.py
Start to create the set over 140000 inputs
CPU Execution time: 2.59375 seconds
We found 24836 duplicates in the input
Wall time (also known as clock time or wall-clock time) is simply the total time
elapsed during the measurement. It’s the time you can measure with a stopwatch.
It is the difference between the time at which a program finished its execution and
the time at which the program started. It also includes waiting time for resources.
CPU Time, on the other hand, refers to the time the CPU was busy processing
the program’s instructions. The time spent waiting for other task to complete
(like I/O operations) is not included in the CPU time. It does not include
the waiting time for resources.
HINT: il faut s'interroger sur les conditions expérimentales. La version du serveur Redis est-elle la même ? Idem pour l'ordinateur qui a exécuté le code. Idem pour la librairie Redis Python utilisée. Est-on sûr que les expériences ont été faites le même jour, sur une machine dont la charge est celle de la première expérience ? Est-ce qu'une seule exécution est suffisante ? Ne doit-on pas faire une quinzaine d'expériences et moyenner les résultats (et calculer aussi l'écart type) ?
Dans le code lecteur.py nous avons implémenté un lecteur, abonné sur le canal 'IUT'. Ce lecteur reçoit des entiers (via un programme que vous devez écrire et qui publie ces entiers) et toutes les minutes il produit la moyenne des valeurs reçues pendant la dernière minute. Nous utilisons le module schedule pour déclencher automatiquement le calcul de la moyenne toutes les minutes. Vous pouvez vous en passer en gardant la trace des secondes qui s'écoulent, et quand vous détectez qu'au moins une minute s'est écoulée (la différence entre une heure sauvegardée et l'heure courrante est plus grande qu'une minute), alors vous calculez la moyenne.
Il y a de nombreuses dificultés d'installation des versions récentes de MondoDB. En effet, les dernières versions utilisent des particularités matérielles des CPU, d'architecture x86_64 en particulier. Il vous faut donc un CPU très récent. Sinon, il vous faudra installer des versions plus anciennes de MongoDB... ce qui n'est pas toujours simple à faire. Nous vous conseillons de suivre les indications suivantes pour les dernières veresions stables de MongoDB :
D'après mon expérience, l'installation d'une version ancienne du serveur MongoDB dans l'image Ubuntu fournie ne fonctionne pas. L'installation dans une image Alpine Linux fonctionne bien. La recompilation des sources est trop compliquée. La virtualisation crée des problèmes. La meilleure chance pour disposer d'un serveur MongoDB semble cependant être de l'installer au même niveau que votre système d'exploitation ou d'utiliser un serveur en ligne fourni par l'organisation MongoDB.
Prenons le cas de Windows. Vous pouvez installer MongoDB en suivant le lien suivant. Je vous conseille également d'installer Compass. Compass est un outil interactif (GUI = Graphical User Interface) gratuit pour interroger, optimiser et analyser vos données MongoDB. Voici maintenant un exemple d'interactions avec le serveur MongoDB Windows et depuis un script Python (librairie pymongo) :
cerin@DESKTOP-J1OM5DL:~$ pip install pymongo
Defaulting to user installation because normal site-packages is not writeable
Collecting pymongo
Downloading pymongo-4.6.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (22 kB)
Collecting dnspython<3.0.0,>=1.16.0 (from pymongo)
Downloading dnspython-2.4.2-py3-none-any.whl.metadata (4.9 kB)
Downloading pymongo-4.6.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (677 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 677.1/677.1 kB 8.6 MB/s eta 0:00:00
Downloading dnspython-2.4.2-py3-none-any.whl (300 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 300.4/300.4 kB 10.6 MB/s eta 0:00:00
Installing collected packages: dnspython, pymongo
Successfully installed dnspython-2.4.2 pymongo-4.6.1
cerin@DESKTOP-J1OM5DL:~$ python3
Python 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pymongo
>>> from pymongo import MongoClient
>>> client = MongoClient()
>>> db = client.test_database
>>> db.test_database["post"]
Collection(Database(MongoClient(host=['localhost:27017'], document_class=dict,
tz_aware=False, connect=True), 'test_database'), 'test_database.post')
>>> db.test_database.post
Collection(Database(MongoClient(host=['localhost:27017'], document_class=dict,
tz_aware=False, connect=True), 'test_database'), 'test_database.post')
>>> db.test_database.post.insert_one({ "foo":"bar"})
InsertOneResult(ObjectId('6574407827655e513af13396'), acknowledged=True)
>>> db.test_database.post
Collection(Database(MongoClient(host=['localhost:27017'], document_class=dict,
tz_aware=False, connect=True), 'test_database'), 'test_database.post')
>>> db.list_collection_names()
['test_database.post']
>>>
>>> db.test_database.post.find_one()
{'_id': ObjectId('6574407827655e513af13396'), 'foo': 'bar'}
>>>
>>> print(db.test_database.post.find({'_id':'6574407827655e513af13396'}))
<pymongo.cursor.Cursor object at 0x7f1bb124fbb0>
>>> import pprint
>>> pprint.pprint(db.test_database.post.find({'_id':'6574407827655e513af13396'}))
<pymongo.cursor.Cursor object at 0x7f1bb124f9a0>
>>>
>>> for doc in db.test_database.post.find():
... print(doc)
...
{'_id': ObjectId('6574407827655e513af13396'), 'foo': 'bar'}
>>>
>>> for doc in db.test_database.post.find():
... print(type(doc['_id']))
...
<class 'bson.objectid.ObjectId'>
>>>
>>> from bson.objectid import ObjectId
>>> db.test_database.post.find_one({'_id':ObjectId('6574407827655e513af13396')})
{'_id': ObjectId('6574407827655e513af13396'), 'foo': 'bar'}
>>>
Veuillez noter ici que MongoDB a été installé au niveau de Windows et que nous travaillons avec Python et le module pymongo dans une machine virtuelle Ubuntu. Depuis la machine virtuelle Ubuntu je peux me connecter au serveur MongoDB. Ainsi, Ubuntu (pour la partie cliente) et Windows (pour la partie serveur) cohabitent et forment un écosystème de bases de données complet.
Une des premières choses à faire est de s'interroger sur les types de données de MongoDB et des opérations de gestion de ces types de données. Le type de données qui est géré par MongoDB est le document. Les documents sont enregistrés eux-mêmes dans des collections, une collection contenant un nombre quelconque de documents. Les collections sont comparables aux tables, et les documents aux enregistrements des bases de données relationnelles. Contrairement aux bases de données relationnelles, les champs d'un enregistrement sont libres et peuvent être différents d'un enregistrement à un autre au sein d'une même collection. Le seul champ commun et obligatoire est le champ de clé principale ("id"). Les collections sont des descriptions « attribut="valeur" », c'est à dire sous la forme d'un dictionnaire ou objet JSON comme on veut ! Voici un exemple de document (exemple repris de la page Wikipedia) :
{
"_id": ObjectId("4efa8d2b7d284dad101e4bc7"),
"Nom": "DUMOND",
"Prénom": "Jean",
"Âge": 43
},
{
"_id": ObjectId("4efa8d2b7d284dad101e4bc8"),
"Nom": "PELLERIN",
"Prénom": "Franck",
"Adresse": "1 chemin des Loges",
"Ville": "VERSAILLES"
},
{
"_id": ObjectId("4efa8d2b7d284dad101e4bc9"),
"Nom": "KING",
"Âge": "51",
"Adresse": "36 quai des Orfèvres",
"Ville": "PARIS"
}
Ce document est formé de trois collections, et nous remarquons que chacune des collections peut avoir des clés de même nom, ou alors des clefs supplémentaires. De plus, un document peut contenir des références à d'autres documents, comme cela est fait à la Figure 2. Leur première utilité est d'accélérer les requêtes de vos applications.

Comme pour tout type de données, nous allons maintenant retrouver les opérations de gestion habituelles, ici déclinées pour le type de données document :
Veuillez remarquer ici que tous les types de données que vous avez étudiés ces dernières années, quelque soit le langage de programmation, avaient cette même boite à outils abstraite.
Dans MongoDB, une opération d'écriture est atomique au niveau d'un seul document, même si l'opération modifie plusieurs documents incorporés dans un seul document. Lorsqu'une seule opération d'écriture modifie plusieurs documents (par exemple db.collection.updateMany()), la modification de chaque document est atomique, mais l'opération dans son ensemble n'est pas atomique.
Les tutoriels qui vous sont proposés, dont celui-ci ou celui-ci pour travailler avec json, vous permettent de vous familiariser, en mode auto-apprentissage, avec les méthodes de gestion d'un document. Attention, il ne s'agit pas de devenir un expert car dans le temps imparti à ce module, nous n'aurons pas l'occasion d'étudier les aspects avancés de MongoDB, comme par exemple les transations, les agrégations, la sécurité, les séries temporelles et le mécanisme dit de sharding (partage). Le partage est une méthode de distribution de données sur plusieurs machines. MongoDB utilise le partitionnement pour prendre en charge les déploiements avec des ensembles de données très volumineux et des opérations à haut débit.
Le code my_json_jointure_for_mongdb.py commence par lire des fichiers CSV sur disque, les converti en JSON, sauvegarde les représentations dans une collection MongoDG, puis passe la main à l'opération de jointure. Cette opération prend en paramètres les identificateurs ('_id') des deux documents d'entrée, et sauvegarde également la jointure dans la collection, en tant que nouveau document. Ici encore l'attribut de jointure est implicite.
Le programme affiche les trois documents présents dans la collection, à savoir, les deux entrées et la jointure :
cerin@DESKTOP-J1OM5DL:~$ python3 my_json_jointure_for_mongdb.py
<class 'pymongo.collection.Collection'> 6574a92798ce13b04c8aa7fc 6574a92798ce13b04c8aa7fd
{'Betty T': {'Test 1': '11.00 / 16', 'Test 2': '11.00 / 18'},
'Cam Chau N': {'Test 1': '6.00 / 16', 'Test 2': '9.00 / 18'},
'Destin L': {'Test 1': '11.00 / 16', 'Test 2': '7.00 / 18'},
'Guillaume C': {'Test 1': '10.00 / 16', 'Test 2': '4.00 / 18'},
'Haytem D': {'Test 1': '12.00 / 16', 'Test 2': '7.00 / 18'},
'Hervé P': {'Test 1': '10.00 / 16', 'Test 2': '12.00 / 18'},
'Joseph L': {'Test 1': '11.00 / 16', 'Test 2': '11.00 / 18'},
'Laurent H': {'Test 1': '15.00 / 16', 'Test 2': '12.00 / 18'},
'Mouloud B': {'Test 1': '13.00 / 16', 'Test 2': '17.00 / 18'},
'Nataliya P': {'Test 1': '10.00 / 16', 'Test 2': '9.00 / 18'},
'Romulus L': {'Test 1': '11.00 / 16', 'Test 2': '11.00 / 18'},
'Rosenthal Preston R': {'Test 1': '13.00 / 16', 'Test 2': '13.00 / 18'},
'Sarra Z': {'Test 1': '11.00 / 16', 'Test 2': '6.00 / 18'},
'Thierno D': {'Test 1': '5.00 / 16', 'Test 2': '8.00 / 18'},
'_id': ObjectId('6574a92798ce13b04c8aa7fc')}
{'Betty T': {'Test 11': '11.00 / 16', 'Test 22': '11.00 / 18'},
'Cam Chau N': {'Test 11': '6.00 / 16', 'Test 22': '9.00 / 18'},
'Destin L': {'Test 11': '11.00 / 16', 'Test 22': '7.00 / 18'},
'Guillaume C': {'Test 11': '10.00 / 16', 'Test 22': '4.00 / 18'},
'Haytem D': {'Test 11': '12.00 / 16', 'Test 22': '7.00 / 18'},
'Hervé P': {'Test 11': '10.00 / 16', 'Test 22': '12.00 / 18'},
'Joseph L': {'Test 11': '11.00 / 16', 'Test 22': '11.00 / 18'},
'Laurent H': {'Test 11': '15.00 / 16', 'Test 22': '12.00 / 18'},
'Mouloud B': {'Test 11': '13.00 / 16', 'Test 22': '17.00 / 18'},
'Nataliya P': {'Test 11': '10.00 / 16', 'Test 22': '9.00 / 18'},
'Romulus L': {'Test 11': '11.00 / 16', 'Test 22': '11.00 / 18'},
'Rosenthal Preston R': {'Test 11': '13.00 / 16', 'Test 22': '13.00 / 18'},
'Sarra Z': {'Test 11': '11.00 / 16', 'Test 22': '6.00 / 18'},
'Thierno D': {'Test 11': '5.00 / 16', 'Test 22': '8.00 / 18'},
'_id': ObjectId('6574a92798ce13b04c8aa7fd')}
{'_id': ObjectId('6574a92798ce13b04c8aa7fe'),
'test': {'Betty T': {'Test 1': '11.00 / 16',
'Test 11': '11.00 / 16',
'Test 2': '11.00 / 18',
'Test 22': '11.00 / 18'},
'Cam Chau N': {'Test 1': '6.00 / 16',
'Test 11': '6.00 / 16',
'Test 2': '9.00 / 18',
'Test 22': '9.00 / 18'},
'Destin L': {'Test 1': '11.00 / 16',
'Test 11': '11.00 / 16',
'Test 2': '7.00 / 18',
'Test 22': '7.00 / 18'},
'Guillaume C': {'Test 1': '10.00 / 16',
'Test 11': '10.00 / 16',
'Test 2': '4.00 / 18',
'Test 22': '4.00 / 18'},
'Haytem D': {'Test 1': '12.00 / 16',
'Test 11': '12.00 / 16',
'Test 2': '7.00 / 18',
'Test 22': '7.00 / 18'},
'Hervé P': {'Test 1': '10.00 / 16',
'Test 11': '10.00 / 16',
'Test 2': '12.00 / 18',
'Test 22': '12.00 / 18'},
'Joseph L': {'Test 1': '11.00 / 16',
'Test 11': '11.00 / 16',
'Test 2': '11.00 / 18',
'Test 22': '11.00 / 18'},
'Laurent H': {'Test 1': '15.00 / 16',
'Test 11': '15.00 / 16',
'Test 2': '12.00 / 18',
'Test 22': '12.00 / 18'},
'Mouloud B': {'Test 1': '13.00 / 16',
'Test 11': '13.00 / 16',
'Test 2': '17.00 / 18',
'Test 22': '17.00 / 18'},
'Nataliya P': {'Test 1': '10.00 / 16',
'Test 11': '10.00 / 16',
'Test 2': '9.00 / 18',
'Test 22': '9.00 / 18'},
'Romulus L': {'Test 1': '11.00 / 16',
'Test 11': '11.00 / 16',
'Test 2': '11.00 / 18',
'Test 22': '11.00 / 18'},
'Rosenthal Preston R': {'Test 1': '13.00 / 16',
'Test 11': '13.00 / 16',
'Test 2': '13.00 / 18',
'Test 22': '13.00 / 18'},
'Sarra Z': {'Test 1': '11.00 / 16',
'Test 11': '11.00 / 16',
'Test 2': '6.00 / 18',
'Test 22': '6.00 / 18'},
'Thierno D': {'Test 1': '5.00 / 16',
'Test 11': '5.00 / 16',
'Test 2': '8.00 / 18',
'Test 22': '8.00 / 18'}}}
cerin@DESKTOP-J1OM5DL:~$
Le code my_json_intersection_for_mongdb.py implémente une opération d'intersection entre les attributs de deux fichiers CSV transformés en JSON. L'algorithme est semblable, dans ses grandes lignes, à l'algorithme vu au précédent paragraphe. C'est la façon de composer l'intersection qui change. Notez également que, comme précédemment, les représentations sont rangées puis lues depuis la base MongoDB. Examinez bien le source code, notamment la fonction intersection(mc,id1,id2), pour comprendre dans quel sens on entend l'intersection afin de produire le résultat suivant :
cerin@DESKTOP-J1OM5DL:~$ python3 my_json_intersection_for_mongdb.py
{'Betty T': {'Test 1': '11.00 / 16', 'Test 2': '11.00 / 18'},
'Cam Chau N': {'Test 1': '6.00 / 16', 'Test 2': '9.00 / 18'},
'Destin L': {'Test 1': '11.00 / 16', 'Test 2': '7.00 / 18'},
'Guillaume C': {'Test 1': '10.00 / 16', 'Test 2': '4.00 / 18'},
'Haytem D': {'Test 1': '12.00 / 16', 'Test 2': '7.00 / 18'},
'Hervé P': {'Test 1': '10.00 / 16', 'Test 2': '12.00 / 18'},
'Joseph L': {'Test 1': '11.00 / 16', 'Test 2': '11.00 / 18'},
'Laurent H': {'Test 1': '15.00 / 16', 'Test 2': '12.00 / 18'},
'Mouloud B': {'Test 1': '13.00 / 16', 'Test 2': '17.00 / 18'},
'Nataliya P': {'Test 1': '10.00 / 16', 'Test 2': '9.00 / 18'},
'Romulus L': {'Test 1': '11.00 / 16', 'Test 2': '11.00 / 18'},
'Rosenthal Preston R': {'Test 1': '13.00 / 16', 'Test 2': '13.00 / 18'},
'Sarra Z': {'Test 1': '11.00 / 16', 'Test 2': '6.00 / 18'},
'Thierno D': {'Test 1': '5.00 / 16', 'Test 2': '8.00 / 18'},
'_id': ObjectId('6575d19195de2399e7b1ac64')}
{'Betty T': {'Test 1': '11.00 / 16',
'Test 2': '11.00 / 18',
'Test 3': '5.00 / 18'},
'Cam Chau N': {'Test 1': '6.00 / 16',
'Test 2': '9.00 / 18',
'Test 3': '12.00 / 18'},
'Destin L': {'Test 1': '11.00 / 16',
'Test 2': '7.00 / 18',
'Test 3': '8.00 / 18'},
'Guillaume C': {'Test 1': '10.00 / 16',
'Test 2': '4.00 / 18',
'Test 3': '10.00 / 18'},
'Haytem D': {'Test 1': '12.00 / 16',
'Test 2': '7.00 / 18',
'Test 3': '10.00 / 18'},
'Hervé P': {'Test 1': '10.00 / 16',
'Test 2': '12.00 / 18',
'Test 3': '10.00 / 18'},
'Joseph L': {'Test 1': '11.00 / 16',
'Test 2': '11.00 / 18',
'Test 3': '8.00 / 18'},
'Laurent H': {'Test 1': '15.00 / 16',
'Test 2': '12.00 / 18',
'Test 3': '7.00 / 18'},
'Mouloud B': {'Test 1': '13.00 / 16',
'Test 2': '17.00 / 18',
'Test 3': '4.00 / 18'},
'Nataliya P': {'Test 1': '10.00 / 16',
'Test 2': '9.00 / 18',
'Test 3': '9.00 / 18'},
'Romulus L': {'Test 1': '11.00 / 16',
'Test 2': '11.00 / 18',
'Test 3': '14.00 / 18'},
'Rosenthal Preston R': {'Test 1': '13.00 / 16',
'Test 2': '13.00 / 18',
'Test 3': '11.00 / 18'},
'Sarra Z': {'Test 1': '11.00 / 16',
'Test 2': '6.00 / 18',
'Test 3': '15.00 / 18'},
'Thierno D': {'Test 1': '5.00 / 16',
'Test 2': '8.00 / 18',
'Test 3': '13.00 / 18'},
'_id': ObjectId('6575d19195de2399e7b1ac65')}
{'_id': ObjectId('6575d19195de2399e7b1ac66'),
'test': {'Betty T': {'Test 1': '["11.00 / 16", "11.00 / 16"]',
'Test 2': '["11.00 / 18", "11.00 / 18"]'},
'Cam Chau N': {'Test 1': '["6.00 / 16", "6.00 / 16"]',
'Test 2': '["9.00 / 18", "9.00 / 18"]'},
'Destin L': {'Test 1': '["11.00 / 16", "11.00 / 16"]',
'Test 2': '["7.00 / 18", "7.00 / 18"]'},
'Guillaume C': {'Test 1': '["10.00 / 16", "10.00 / 16"]',
'Test 2': '["4.00 / 18", "4.00 / 18"]'},
'Haytem D': {'Test 1': '["12.00 / 16", "12.00 / 16"]',
'Test 2': '["7.00 / 18", "7.00 / 18"]'},
'Hervé P': {'Test 1': '["10.00 / 16", "10.00 / 16"]',
'Test 2': '["12.00 / 18", "12.00 / 18"]'},
'Joseph L': {'Test 1': '["11.00 / 16", "11.00 / 16"]',
'Test 2': '["11.00 / 18", "11.00 / 18"]'},
'Laurent H': {'Test 1': '["15.00 / 16", "15.00 / 16"]',
'Test 2': '["12.00 / 18", "12.00 / 18"]'},
'Mouloud B': {'Test 1': '["13.00 / 16", "13.00 / 16"]',
'Test 2': '["17.00 / 18", "17.00 / 18"]'},
'Nataliya P': {'Test 1': '["10.00 / 16", "10.00 / 16"]',
'Test 2': '["9.00 / 18", "9.00 / 18"]'},
'Romulus L': {'Test 1': '["11.00 / 16", "11.00 / 16"]',
'Test 2': '["11.00 / 18", "11.00 / 18"]'},
'Rosenthal Preston R': {'Test 1': '["13.00 / 16", "13.00 / 16"]',
'Test 2': '["13.00 / 18", "13.00 / 18"]'},
'Sarra Z': {'Test 1': '["11.00 / 16", "11.00 / 16"]',
'Test 2': '["6.00 / 18", "6.00 / 18"]'},
'Thierno D': {'Test 1': '["5.00 / 16", "5.00 / 16"]',
'Test 2': '["8.00 / 18", "8.00 / 18"]'}}}
cerin@DESKTOP-J1OM5DL:~$
Les indexes permettent une exécution efficace des requêtes dans MongoDB. Sans indexe, MongoDB doit analyser i.e. parcourir séquentiellement chaque document d'une collection pour renvoyer les résultats de la requête. Si un indexe approprié existe pour une requête, MongoDB l'utilise pour limiter le nombre de documents à consulter.
Bien que les indexes améliorent les performances des requêtes, l'ajout d'un indexe a un impact négatif sur les performances des opérations d'écriture. Pour les collections dont le ratio écriture/lecture est élevé, les indexes sont coûteux car chaque insertion doit également mettre à jour les indexes. C'est un peu ce qui nous arrive avec le code ci-après.
En effet, pour le code qui suit, nous réalisons l'insertion d'un nouveau mot à partir du moment où ce mot n'est pas déjà présent dans le dictionnaire. Il y a donc autant (modulo les mots en double) de lectures dans la collection que d'écritures. Cette opération de test et d'ajout si le mot n'est pas présent est réalisée par le codage mycol.replace_one({my_row['M']: 1},{my_row['M']:1},upsert=True,hint=[ ('M', 1) ]). Veuillez vous reporter à la documentation de replace_one() pour plus de détails, dont l'argument hint qui permet de passer explicitement en argument l'indexe.
L'exécution du programme my_index_mongo.py donne le résultat suivant sur ma machine (il faudrait détailler les conditions expérimentales afin d'expliquer plus en détail le résultat -- Le dictionnaire de mots, utilisé par le programme, est ici. Il est de taille 8.5Mo.) :
cerin@DESKTOP-J1OM5DL:~$ python my_index_mongo.py
Start performance eval over 14000 inputs
CPU Execution time: 3.828125 seconds
We found 1509 duplicates in the input
Wall time (also known as clock time or wall-clock time) is simply the total time
elapsed during the measurement. It’s the time you can measure with a stopwatch.
It is the difference between the time at which a program finished its execution and
the time at which the program started. It also includes waiting time for resources.
CPU Time, on the other hand, refers to the time the CPU was busy processing
the program’s instructions. The time spent waiting for other task to complete
(like I/O operations) is not included in the CPU time. It does not include
the waiting time for resources.
cerin@DESKTOP-J1OM5DL:~$
Les indexes sont des structures de données spéciales qui stockent une petite partie de l'ensemble des données de la collection sous une forme facile à parcourir. Les indexes de MongoDB utilisent la structure de données de B-arbre.
L'indexe stocke la valeur d'un champ spécifique ou d'un ensemble de champs, ordonnée selon la valeur du champ. L'ordre des entrées de l'indexe prend en charge les correspondances d'égalité et les opérations d'interrogation basées sur la plage. En outre, MongoDB peut renvoyer des résultats triés en utilisant l'ordre de l'indexe.
Certaines restrictions s'appliquent aux indexes, telles que la longueur des clés d'indexe ou le nombre d'indexes par collection. Pour plus de détails, vuillez vous reporter à la documentation.
MongoDB crée un indexe unique sur le champ _id lors de la création d'une collection. L'indexe _id empêche les clients d'insérer deux documents ayant la même valeur pour le champ _id. Vous ne pouvez pas supprimer cet indexe.
Une clause ou requête complexe en MongoDB correspond aux clauses SQL avec des group by, where.... Elles sont nécessaires pour explorer une collection et filtrer cette collection sur des attributs spécifiques. Ainsi, les documents vérifiant une certaine propriété sont isolés. Le code my_dico_mongo.py construit une collection de mots du dictionnaire, puis filtre cette collection pour repérer le nombre de définitions associé à chaque mot, et enfin fusionne les définitions de chaque mot dans une liste. C'est la notion d'agrégation qui est explorée dans ce code. Le code proposé met en oeuvre, pour certaines parties, un pipeline, c'est à dire la combinaison de plusieurs opérations afin de construire le résultat attendu. Le pipeline exprime donc la propriété permettant de filter la collection.
L'exécution du programme my_dico_mongo.py donne la trace suivante :
cerin@DESKTOP-J1OM5DL:~$ python my_dico_mongo.py
Start performance eval over 100 inputs
CPU Execution time: 0.0 seconds
Wall time (also known as clock time or wall-clock time) is simply the total time
elapsed during the measurement. It’s the time you can measure with a stopwatch.
It is the difference between the time at which a program finished its execution and
the time at which the program started. It also includes waiting time for resources.
CPU Time, on the other hand, refers to the time the CPU was busy processing
the program’s instructions. The time spent waiting for other task to complete
(like I/O operations) is not included in the CPU time. It does not include
the waiting time for resources.
================================================
Find all definition(s) for word "à cheval sur"
================================================
{'_id': ObjectId('657ecd521dc9c5a832b6286f'), 'M': 'à cheval sur', 'SENS': '(assis)à califourchon'}
{'_id': ObjectId('657ecd521dc9c5a832b62870'), 'M': 'à cheval sur', 'SENS': 'intransigeant sr qc'}
{'_id': ObjectId('657ecd521dc9c5a832b62871'), 'M': 'à cheval sur', 'SENS': 'ne pas transiger sur'}
================================
Number of definitions per word
================================
{'_id': 'à bras ouverts', 'Total': 1}
{'_id': 'à cent pour cent', 'Total': 1}
{'_id': 'à bon marché', 'Total': 2}
{'_id': 'à ce régime', 'Total': 1}
{'_id': 'à brûle-pourpoint', 'Total': 1}
{'_id': 'à cause que', 'Total': 1}
{'_id': 'à boucheton', 'Total': 1}
{'_id': 'à bras tendus', 'Total': 1}
{'_id': 'à côté de ses pompes', 'Total': 1}
{'_id': 'à bloc', 'Total': 1}
{'_id': 'à coups de cuiller à pot', 'Total': 1}
{'_id': 'à aucun moment', 'Total': 1}
{'_id': 'à chaque instant', 'Total': 1}
{'_id': 'à coeur ouvert', 'Total': 1}
{'_id': 'à bas prix', 'Total': 1}
{'_id': 'à côté de la plaque', 'Total': 1}
{'_id': 'à bras-le-corps', 'Total': 1}
{'_id': 'à ce jour', 'Total': 1}
{'_id': 'à cela près', 'Total': 1}
{'_id': 'à bon entendeur salut', 'Total': 1}
{'_id': "à cent sous de l'heure", 'Total': 1}
{'_id': 'à', 'Total': 1}
{'_id': 'à ces mots', 'Total': 1}
{'_id': 'à chaque pas', 'Total': 1}
{'_id': 'à cette fin que', 'Total': 1}
{'_id': 'à ciel ouvert', 'Total': 1}
{'_id': 'à condition de', 'Total': 1}
{'_id': 'à bout de bras', 'Total': 2}
{'_id': 'à contre-lit', 'Total': 1}
{'_id': 'à cheval sur', 'Total': 3}
{'_id': 'à bout de course', 'Total': 1}
{'_id': 'a contrario', 'Total': 1}
{'_id': 'à claire-voie', 'Total': 1}
{'_id': 'à côté de', 'Total': 2}
{'_id': 'à bientôt', 'Total': 1}
{'_id': 'à bon escient', 'Total': 1}
{'_id': 'à bouche que veux-tu', 'Total': 1}
{'_id': 'à compter de tant', 'Total': 1}
{'_id': 'à bon prix', 'Total': 1}
{'_id': 'à bras', 'Total': 1}
{'_id': 'a', 'Total': 2}
{'_id': 'à bout portant', 'Total': 1}
{'_id': 'à bonne distance', 'Total': 1}
{'_id': 'à bras raccourcis', 'Total': 1}
{'_id': 'à ce compte-là', 'Total': 1}
{'_id': 'à ce titre', 'Total': 1}
{'_id': 'à cette heure', 'Total': 1}
{'_id': 'à aucun prix', 'Total': 1}
{'_id': 'à clin', 'Total': 1}
{'_id': 'à coeur', 'Total': 1}
{'_id': 'à confesse', 'Total': 1}
{'_id': 'à contrecoeur', 'Total': 1}
{'_id': 'à cor et à cri', 'Total': 1}
{'_id': 'à bonne enseigne', 'Total': 1}
{'_id': 'à contretemps', 'Total': 1}
{'_id': 'à côté', 'Total': 1}
{'_id': 'à bout touchant', 'Total': 1}
{'_id': 'à bureaux fermés', 'Total': 1}
{'_id': 'à courre', 'Total': 1}
{'_id': 'à califourchon', 'Total': 1}
{'_id': 'à base de', 'Total': 1}
{'_id': 'à charge de', 'Total': 1}
{'_id': 'à corps perdu', 'Total': 1}
{'_id': 'à côté de ça', 'Total': 1}
{'_id': 'à chaud', 'Total': 1}
{'_id': 'à bâtons rompus', 'Total': 1}
{'_id': 'à coups de', 'Total': 1}
{'_id': 'à beaucoup près', 'Total': 1}
{'_id': 'à ce point', 'Total': 1}
{'_id': 'à bas', 'Total': 1}
{'_id': 'à cet effet', 'Total': 1}
{'_id': 'à contre-passe', 'Total': 1}
{'_id': 'à charge de revanche', 'Total': 1}
{'_id': 'à coup sûr', 'Total': 1}
{'_id': 'à condition que', 'Total': 2}
{'_id': 'à bout de souffle', 'Total': 1}
{'_id': 'à bon droit', 'Total': 1}
{'_id': 'à coucher dehors', 'Total': 1}
{'_id': 'à brève échéance', 'Total': 1}
{'_id': 'à bride abattue', 'Total': 1}
{'_id': 'à contre-poil', 'Total': 1}
{'_id': 'à cette date', 'Total': 1}
{'_id': 'à charge', 'Total': 1}
{'_id': 'à cocourant', 'Total': 1}
{'_id': "à compte d'auteur", 'Total': 1}
{'_id': 'à bord de', 'Total': 1}
{'_id': 'à contre-courant', 'Total': 1}
{'_id': 'à contresens', 'Total': 1}
{'_id': 'à bref délai', 'Total': 1}
{'_id': 'a capella', 'Total': 1}
{'_id': 'à coups de hache', 'Total': 1}
{'_id': 'à cet égard', 'Total': 1}
{'_id': 'à contre-bord', 'Total': 1}
==============================
Merging of definitions
==============================
{'_id': 'à bonne distance', 'meaning': ["(se tenir)à l'écart"]}
{'_id': 'à ce compte-là', 'meaning': ['en conclusion']}
{'_id': 'à ce titre', 'meaning': ['pr cette raison']}
{'_id': 'à cette heure', 'meaning': ['maintenant']}
{'_id': 'à aucun prix', 'meaning': ['(céder)en aucun cas']}
{'_id': 'à bonne enseigne', 'meaning': ['av solides granties']}
{'_id': 'à clin', 'meaning': ['d type revêtement']}
{'_id': 'à confesse', 'meaning': ['confession']}
{'_id': 'à califourchon', 'meaning': ['(assis)jambe d chaq côt']}
{'_id': 'à contrecoeur', 'meaning': ['à regret']}
{'_id': 'à base de', 'meaning': ['d composant principal']}
{'_id': 'à charge de', 'meaning': ["ds l'obligation de"]}
{'_id': 'à contretemps', 'meaning': ['mal à propos']}
{'_id': 'à bout touchant', 'meaning': ['(tirer)e touchant corps']}
{'_id': 'à bureaux fermés', 'meaning': ['ss nveaux assistants']}
{'_id': 'à cor et à cri', 'meaning': ['(crier)à grand bruit']}
{'_id': 'à courre', 'meaning': ['(chasse)à la poursuite']}
{'_id': 'à beaucoup près', 'meaning': ['à forte différence près']}
{'_id': 'à ce point', 'meaning': ['à tel degré élevé']}
{'_id': 'à bas', 'meaning': ['hostilité à N']}
{'_id': 'à cet effet', 'meaning': ['en vue d cela']}
{'_id': 'à contre-passe', 'meaning': ['d forme d sciage']}
{'_id': 'à chaud', 'meaning': ['en pleine crise']}
{'_id': 'à bâtons rompus', 'meaning': ['ss suite,d f discontinu']}
{'_id': 'à corps perdu', 'meaning': ['en prenant ts risques']}
{'_id': 'à coups de', 'meaning': ['en multipliant actes']}
{'_id': 'à charge de revanche', 'meaning': ['en rendant même service']}
{'_id': 'à coup sûr', 'meaning': ['sûrement']}
{'_id': 'à côté de ça', 'meaning': ['p ailleurs']}
{'_id': 'à bon droit', 'meaning': ['(réclamer)en tte justice']}
{'_id': 'à coucher dehors', 'meaning': ['(nom)imprononçable']}
{'_id': 'à condition que', 'meaning': ['sous réserve que', 'sous réserve que']}
{'_id': 'à bout de souffle', 'meaning': ['(qn)ê épuisé']}
{'_id': 'à cette date', 'meaning': ['à ce moment']}
{'_id': 'à charge', 'meaning': ["q relève d l'auteur"]}
{'_id': 'à cocourant', 'meaning': ['(aller)ds le même sens']}
{'_id': 'à bride abattue', 'meaning': ['à tte vitesse d cheval']}
{'_id': 'à brève échéance', 'meaning': ['ds peu d tps (date)']}
{'_id': 'à contre-poil', 'meaning': ['(aller)à sens opposé']}
{'_id': 'à contresens', 'meaning': ['(aller)en sens contrair']}
{'_id': 'à bref délai', 'meaning': ['ds peu d tps (durée)']}
{'_id': 'a capella', 'meaning': ['ss accompagnement']}
{'_id': "à compte d'auteur", 'meaning': ["aux frais d l'auteur"]}
{'_id': 'à bord de', 'meaning': ['ds véh,ds bateau']}
{'_id': 'à contre-courant', 'meaning': ['(aller)en sens opposé']}
{'_id': 'à coups de hache', 'meaning': ['grossièrement']}
{'_id': 'à contre-bord', 'meaning': ["à l'opposé d autre"]}
{'_id': 'à cet égard', 'meaning': ['sr ce point,à ce sujet']}
{'_id': 'à ce régime', 'meaning': ['en agissant ainsi']}
{'_id': 'à brûle-pourpoint', 'meaning': ['d faç immédiate,brutale']}
{'_id': 'à bras ouverts', 'meaning': ['(accueilir)cordialement']}
{'_id': 'à cent pour cent', 'meaning': ['complètement,totalement']}
{'_id': 'à bon marché', 'meaning': ['(vente/achat)à prix bas', 'ss grds inconvénients']}
{'_id': 'à bloc', 'meaning': ['à fond,au maximum']}
{'_id': 'à coups de cuiller à pot', 'meaning': ['très rapidement']}
{'_id': 'à cause que', 'meaning': ['cause,explication']}
{'_id': 'à boucheton', 'meaning': ['façon d placer poterie']}
{'_id': 'à bras tendus', 'meaning': ['bras écartés et tendus']}
{'_id': 'à côté de ses pompes', 'meaning': ['(ê)fou,désorienté']}
{'_id': 'à bas prix', 'meaning': ['(vendre)à bon marché']}
{'_id': 'à côté de la plaque', 'meaning': ['(ê)fou,hors sujet']}
{'_id': 'à aucun moment', 'meaning': ['jamais']}
{'_id': 'à chaque instant', 'meaning': ['continuellement']}
{'_id': 'à coeur ouvert', 'meaning': ['(parler)franchement']}
{'_id': 'à bon entendeur salut', 'meaning': ['avertissement donné à']}
{'_id': "à cent sous de l'heure", 'meaning': ['énormément']}
{'_id': 'à', 'meaning': ['(qc)appartenir à qn,qc / à N (ê)']}
{'_id': 'à chaque pas', 'meaning': ['à chaque instant']}
{'_id': 'à ciel ouvert', 'meaning': ["(ê)à l'air libre"]}
{'_id': 'à bras-le-corps', 'meaning': ['(tenir)au milieu d corp']}
{'_id': 'à ce jour', 'meaning': ["aujourd'hui"]}
{'_id': 'à cela près', 'meaning': ['approximation']}
{'_id': 'à bout de bras', 'meaning': ['tenir av effort pr aide', '(tenir)qc à bras tendu']}
{'_id': 'à ces mots', 'meaning': ['après av entend cela']}
{'_id': 'à cheval sur', 'meaning': ['(assis)à califourchon', 'intransigeant sr qc', 'ne pas transiger sur']}
{'_id': 'à contre-lit', 'meaning': ['(bloc,pierre)en délit']}
{'_id': 'à condition de', 'meaning': ['moyennant qc']}
{'_id': 'à cette fin que', 'meaning': ['dans le but de,sue']}
{'_id': 'à claire-voie', 'meaning': ['(barrière)q p ê ouverte']}
{'_id': 'à côté de', 'meaning': ['(aller)auprès de', 'en comparaison de']}
{'_id': 'à bout de course', 'meaning': ['(qn)ê épuisé']}
{'_id': 'a contrario', 'meaning': ["à l'inverse"]}
{'_id': 'à compter de tant', 'meaning': ['à dater de,depuis tps']}
{'_id': 'à bon prix', 'meaning': ['(acheter)bon marché']}
{'_id': 'à bientôt', 'meaning': ['au revoir']}
{'_id': 'à bon escient', 'meaning': ['(agir)à propos']}
{'_id': 'à bras', 'meaning': ['(tenir)p force d bras']}
{'_id': 'à bouche que veux-tu', 'meaning': ['(donner)à profusion']}
{'_id': 'à côté', 'meaning': ['(ê)à proximité']}
{'_id': 'à coeur', 'meaning': ["jusqu'au centre d aliment"]}
{'_id': 'à bras raccourcis', 'meaning': ['d ttes forces des bras']}
{'_id': 'a', 'meaning': ['alphabet latin', 'ouverte']}
{'_id': 'à bout portant', 'meaning': ['(tirer)d sr très près']}
cerin@DESKTOP-J1OM5DL:~$
Nota : L'agrégation lookup permet de réaliser des jointures, en l'occurence une left outer join. La discussion initiale sur l'agrégation lookup introduite dans MongoDB 3.2, mérite d'être lue ainsi que l'exemple sur W3schools. Vous pouvez ensuite vous demander comment implémenter en MongoDB et avec l'agrégation lookup les différentes opérations SQL de jointure comme le NATURAL JOIN, le RIGHT JOIN…
Le code join.py est un premier exemple d'agrégation. Dans le résultat d'agrégation qui suit, on remarquera l'attribut AuthorDetail qui agrège les documents de la collection Authors quand il y a une correspondance entre Author_id de Books et _id de Authors :
cerin@DESKTOP-J1OM5DL:~$ python join.py Type agrégation:===== Agrégation ===== {'AuthorDetail': [{'_id': 1, 'name': 'william shakespeare'}], '_id': 1, 'author_id': 1, 'price': 100, 'title': 'The Alchemist'} {'AuthorDetail': [{'_id': 2, 'name': 'David copperfield'}], '_id': 2, 'author_id': 2, 'price': 200, 'title': 'Charles Dicken'} {'AuthorDetail': [{'_id': 1, 'name': 'william shakespeare'}], '_id': 3, 'author_id': 1, 'price': 300, 'title': 'The Pilgrimage'} {'AuthorDetail': [{'_id': 3, 'name': 'Paulo coelho'}], '_id': 4, 'author_id': 3, 'price': 400, 'title': 'Othello'}
Le code join_bis.py reprend les idées du premier exemple d'agrégation. Dans le résultat d'agrégation qui suit, on remarquera l'attribut Detail qui agrège les documents de la collection Matiere1 quand il y a une correspondance entre Prenom_nom de Matiere1 et Nom de Matiere2. On obtient ici une représentation d'un SQL FULL JOIN modulo le fait que l'information servant à la jointure apparait deux fois :
cerin@DESKTOP-J1OM5DL:~$ python join_bis.py Type agrégation:===== Agrégation ===== {'Detail': [{'Nom': 'Hervé P', 'T_1': '10.00 / 16', 'T_2': '12.00 / 18', 'T_3': '10.00 / 18', '_id': ObjectId('658d666cfd502db097290e91')}], 'Prenom_nom': 'Hervé P', 'Test_1': '10.00 / 16', 'Test_2': '12.00 / 18', '_id': ObjectId('658d666cfd502db097290e83')} {'Detail': [{'Nom': 'Laurent H', 'T_1': '15.00 / 16', 'T_2': '12.00 / 18', 'T_3': '7.00 / 18', '_id': ObjectId('658d666cfd502db097290e92')}], 'Prenom_nom': 'Laurent H', 'Test_1': '15.00 / 16', 'Test_2': '12.00 / 18', '_id': ObjectId('658d666cfd502db097290e84')} {'Detail': [{'Nom': 'Destin L', 'T_1': '11.00 / 16', 'T_2': '7.00 / 18', 'T_3': '8.00 / 18', '_id': ObjectId('658d666cfd502db097290e93')}], 'Prenom_nom': 'Destin L', 'Test_1': '11.00 / 16', 'Test_2': '7.00 / 18', '_id': ObjectId('658d666cfd502db097290e85')} {'Detail': [{'Nom': 'Guillaume C', 'T_1': '10.00 / 16', 'T_2': '4.00 / 18', 'T_3': '10.00 / 18', '_id': ObjectId('658d666cfd502db097290e94')}], 'Prenom_nom': 'Guillaume C', 'Test_1': '10.00 / 16', 'Test_2': '4.00 / 18', '_id': ObjectId('658d666cfd502db097290e86')} {'Detail': [{'Nom': 'Haytem D', 'T_1': '12.00 / 16', 'T_2': '7.00 / 18', 'T_3': '10.00 / 18', '_id': ObjectId('658d666cfd502db097290e95')}], 'Prenom_nom': 'Haytem D', 'Test_1': '12.00 / 16', 'Test_2': '7.00 / 18', '_id': ObjectId('658d666cfd502db097290e87')} {'Detail': [{'Nom': 'Cam Chau N', 'T_1': '6.00 / 16', 'T_2': '9.00 / 18', 'T_3': '12.00 / 18', '_id': ObjectId('658d666cfd502db097290e96')}], 'Prenom_nom': 'Cam Chau N', 'Test_1': '6.00 / 16', 'Test_2': '9.00 / 18', '_id': ObjectId('658d666cfd502db097290e88')} {'Detail': [{'Nom': 'Sarra Z', 'T_1': '11.00 / 16', 'T_2': '6.00 / 18', 'T_3': '15.00 / 18', '_id': ObjectId('658d666cfd502db097290e97')}], 'Prenom_nom': 'Sarra Z', 'Test_1': '11.00 / 16', 'Test_2': '6.00 / 18', '_id': ObjectId('658d666cfd502db097290e89')} {'Detail': [{'Nom': 'Romulus L', 'T_1': '11.00 / 16', 'T_2': '11.00 / 18', 'T_3': '14.00 / 18', '_id': ObjectId('658d666cfd502db097290e98')}], 'Prenom_nom': 'Romulus L', 'Test_1': '11.00 / 16', 'Test_2': '11.00 / 18', '_id': ObjectId('658d666cfd502db097290e8a')} {'Detail': [{'Nom': 'Thierno D', 'T_1': '5.00 / 16', 'T_2': '8.00 / 18', 'T_3': '13.00 / 18', '_id': ObjectId('658d666cfd502db097290e99')}], 'Prenom_nom': 'Thierno D', 'Test_1': '5.00 / 16', 'Test_2': '8.00 / 18', '_id': ObjectId('658d666cfd502db097290e8b')} {'Detail': [{'Nom': 'Rosenthal Preston R', 'T_1': '13.00 / 16', 'T_2': '13.00 / 18', 'T_3': '11.00 / 18', '_id': ObjectId('658d666cfd502db097290e9a')}], 'Prenom_nom': 'Rosenthal Preston R', 'Test_1': '13.00 / 16', 'Test_2': '13.00 / 18', '_id': ObjectId('658d666cfd502db097290e8c')} {'Detail': [{'Nom': 'Betty T', 'T_1': '11.00 / 16', 'T_2': '11.00 / 18', 'T_3': '5.00 / 18', '_id': ObjectId('658d666cfd502db097290e9b')}], 'Prenom_nom': 'Betty T', 'Test_1': '11.00 / 16', 'Test_2': '11.00 / 18', '_id': ObjectId('658d666cfd502db097290e8d')} {'Detail': [{'Nom': 'Mouloud B', 'T_1': '13.00 / 16', 'T_2': '17.00 / 18', 'T_3': '4.00 / 18', '_id': ObjectId('658d666cfd502db097290e9c')}], 'Prenom_nom': 'Mouloud B', 'Test_1': '13.00 / 16', 'Test_2': '17.00 / 18', '_id': ObjectId('658d666cfd502db097290e8e')} {'Detail': [{'Nom': 'Joseph L', 'T_1': '11.00 / 16', 'T_2': '11.00 / 18', 'T_3': '8.00 / 18', '_id': ObjectId('658d666cfd502db097290e9d')}], 'Prenom_nom': 'Joseph L', 'Test_1': '11.00 / 16', 'Test_2': '11.00 / 18', '_id': ObjectId('658d666cfd502db097290e8f')} {'Detail': [{'Nom': 'Nataliya P', 'T_1': '10.00 / 16', 'T_2': '9.00 / 18', 'T_3': '9.00 / 18', '_id': ObjectId('658d666cfd502db097290e9e')}], 'Prenom_nom': 'Nataliya P', 'Test_1': '10.00 / 16', 'Test_2': '9.00 / 18', '_id': ObjectId('658d666cfd502db097290e90')}
Le code my_json_agregation_join.py est un deuxième exemple d'agrégation et ce code utilise les fichiers CSV test_join.csv et test2_join.csv. Son exécution ne donne pas le résultat escompté car il ne produit rien pour l'attribut join_sample de l'agrégation. Veuillez expliquer et corriger le code.
HINT: il ne s'agit pas d'une erreur dans la spécification de l'agrégation, mais d'une erreur de gestion de la base de donnée mydb. Le code qui fonctionne est my_json_agregation_bis_join.py.
Le code my_json_agregation_ter_join.py est un autre exemple d'agrégation et ce code utilise de nouveau les fichiers d'entrée CSV test_join.csv et test2_join.csv. Cependant, de nouvelles fonctionnalités sont utilisées :
cerin@DESKTOP-J1OM5DL:~$ python my_json_agregation_ter_join.py Type agrégation:===== Agrégation ===== ObjectId('658d9fd3673eb3561e414865') Nom : BETTY T Note 1 : 11.00 / 18 Note 2 : 11.00 / 16 Note 3 : 11.00 / 18 Note 4 : 11.00 / 18 Note 5 : 11.00 / 16 ------------------------ ObjectId('658d9fd3673eb3561e414861') Nom : SARRA Z Note 1 : 6.00 / 18 Note 2 : 11.00 / 16 Note 3 : 6.00 / 18 Note 4 : 6.00 / 18 Note 5 : 11.00 / 16 ------------------------