![]()
![]() (a
est une constante comprise entre 0 et 1)
(a
est une constante comprise entre 0 et 1)
Exercices sur l'ordonnancement,
la communication locale sous Unix
Préambule
Le schéma de base d'utilisation de fork() a été vu en cours et il est disponible en suivant ce lien : http://www-lipn.univ-paris13.fr/~cerin/SE/fork1.c On modifie le schéma comme suit :
#include <stdio.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
int pid;
/* fork another process */
pid = fork();
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
exit(-1);
}
else if (pid == 0) { /* child process */
printf("toto");
}
else { /* parent process */
/* parent will wait for the child to complete */
printf("titi");
wait(NULL);
exit(0);
}
}Comme il y a un test dans le programme, soit le printf(toto) soit le printf(titi) aura lieu. Etes vous d'accord avec cela ? Si ce n'est pas le cas, expliquez ce qui va se passer à l'exécution.
On propose maintenant le code suivant et nous affirmons que l'affichage ne peut être que toto suivi de titi suivi de tata ou titi suivi de toto suivi de tata. On ne peut jamais avoir comme premier affichage tata. Etes vous d'accord avec ces affirmations ?
#include <stdio.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
int pid;
/* fork another process */
pid = fork();
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
exit(-1);
}
else if (pid == 0) { /* child process */
printf("toto");
}
else { /* parent process */
/* parent will wait for the child to complete */
printf("titi");
wait(NULL);
printf("tata");
exit(0);
}
}
On modifie de nouveaux le schéma de base comme suit :
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main(int argc, char *argv[])
{
int status;
pid_t wpid, pid;
/* fork another process */
pid = fork();
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
exit(-1);
}
else if (pid == 0) { /* child process */
printf("toto");
wpid = waitpid(getppid(), &status, WNOHANG);
}
else { /* parent process */
/* parent will wait for the child to complete */
wait(NULL);
printf("tata");
exit(0);
}
}Cette implémentation utilise la fonction waitpid qui permet de contrôler la terminaison d'un processus particulier. Que va t'il se passer avec le code donné ? Attention, il faut bien voir ici que l'instruction waitpid n'est pas bloquante (faire un man waitpid).
0- Compilation, pthread et GNU PTH
Cet exercice a pour objectif de faire une révision sur les techniques de compilation en même temps que de découvrir des interfaces de programmation de gestion des processus.
Premièrement, veuillez récupérer le fichier http://www-lipn.univ-paris13.fr/~cerin/SE/pthread_perf.c. Que fait ce programme qui utilise l'interface de programmation fork/wait et aussi l'interface pthread_create/pthread_join ? Compilez-le. Exécutez le. Mesurez les temps d'exécution des deux interfaces de programmation de création des processus. Quelle interface vous semble t-elle la plus performante ?
Veuillez ensuite installer GNU Pth (http://www.gnu.org/software/pth) dans /tmp. Pour cela, après le ./configure, veuillez modifier la variable prefix dans le fichier Makefile. Faites ensuite un make et un make install (éventuellement un make test pour vérifier que tout va bien).
Puis, à partir des exemples test_*.c qui sont dans la distribution de PTH, adapter le code pthread_perf.c afin de créer une troisième fonction qui sera programmée au moyen des primitives de gestion des processus offertes par Pth et qui, comme les deux autres fonctions, réalisera la création/synchronisation de NB processus. Est-ce que Pth est plus performante que les deux autres interfaces ?
Enfin, adapter votre solution pour faire en sorte de créer deux processus à chaque itération (et non pas un seul) ainsi que les synchronisations nécessaires entre ces deux processus (avant de passer à l'itération suivante).
1- Mémoire partagée (mmap)
1.1 Ecrire un programme ou deux processus effectuent concurremment la somme de deux matrices : si je suis le père, je fais la somme sur les indices pairs, si je suis le fils je fais la somme sur les indices impairs. On fera également l’affichage de la matrice « somme » (à votre avis, dans le père ou dans le fils ?).
1.2 Même question pour le produit de matrices carrées : les processus père et fils calculent alternativement une ligne du résultat selon que l’indice des lignes dans la matrice résultat est pair ou impair. A votre avis, est-ce que votre code fait des accès concurrents en lecture à la mémoire ? Est-ce génant ?
1.3 Reprendre le code qui effectue l’approximation de PI et implémentez-le avec de la mémoire partagée pour pouvoir faire, conceptuellement, area1+area2. Après ce travail, modifier votre nouveau code pour qu’il y ait 4 processus, chacun calculant 1/4 de l’aire.
1.4 Soient les deux processus P1 et P2 suivants qui s'exécutent concurremment et qui accèdent à la variable commune (partagée) N :processus P1: processus P2: ..... ..... load r1, N load r2,N add r1,r1, 1 add r2,r2,1 store r1,N store r2, N exit exit
Vous savez qu'une instruction de type N = N+1 n'est pas atomique (l'ordonnanceur peut passer la main à un autre processus avant qu'elle se termine). Donnez deux scénarii d'exécution de P1 et P2 qui conduisent à deux valeurs distinctes pour N lorsque P1 et P2 sont terminés.
Vous pouvez construire vos scénarii en composant un programme avec les instructions de P1 et les instructions de P2..; mais en préservant l'ordre interne des opérations (vous ne pouvez pas faire dans cet ordre un store r1,N puis load r1, N). En mélangeant les instructions de la sorte, combien de programmes pouvez-vous construire ?
1.5 On rappelle que la fonction log(x+1) peut être approchée par le développement suivant à l’ordre 12: x-1/2*x^2+1/3*x^3-1/4*x^4+1/5*x^5-1/6*x^6+1/7*x^7-1/8*x^8+1/9*x^9-1/10*x^10+1/11*x^11+O(x^12) et pour -1 < x <= 1, x étant un réel. Ecrire un programme a deux processus qui lit une valeur pour x et un ordre de grandeur k et qui calcule log(x+1) à l’ordre k avec la formule précédente : le père calcule les puissances paires et le fils les puissances impaires. Vous pouvez appliquer l’algorithme suivant :
a) Le père (seul) commence par ranger dans un tableau T partagé les puissances : T[0]=1, T[1]=x, T[2]=x*x, T[3]=x*x*x…
b) Le père et le fils multiplient chacune des puissances par le coefficient approprié (père traite les puissances paires, le fils les puissances impaires) afin de calculer les sommes partielles ;
c) Il reste a faire la somme des deux sommes partielles (par le père ou le fils ?) et d’afficher le résultat.
Un autre algorithme est possible. Contrairement au précédent, la première phase (calcul des T[i]) peut être réalisée par le père et le fils sous les contraintes suivantes : le père calcule les T[i] pour i pairs, le fils les T[i] pour les i impairs. Cependant on ne peut produire T[i] que si T[i-1] a été produit en faisant T[i]=T[i-1]*x. Cela séquentialise le code et fait intervenir des synchronisations entre le père et le fils. La synchronisation entre le père et le fils peut s'implémenter par le pseudo code suivant (on initialise une variable semaphore à 1 juste avant un fork – semaphore est une variable en mémoire partagée):
Processus exécuté par le père : Etiq1: while(est_impair(semaphore)) attendre; T[semaphore] = T[semaphore-1]*x; semaphore++; goto Etiq1; |
Processus exécuté par le fils : Etiq2: while(est_pair(semaphore)) attendre; T[semaphore] = T[semaphore-1]*x; semaphore++; goto Etiq2; |
1.6 Dans l'exercice précédent, l'instruction T[semaphore] = T[semaphore-1]*x; constitue la section critique c'est à dire le code qui ne peut être accédé que par au plus un processus. Recoder l'exercice précédent au moyen de l'algorithme de Perterson suivant qui assure l'exclusion mutuelle :
shared boolean wantIn[2]=false,false;
shared int turn = 1;
int myPid = 0; //pour le processus pere et init à 1 pour le fils
int otherPid = 1 – mypid;
while(true){
wantIn[myPid] = true;
turn = otherPid;
while wantIn[otherPid] && (turn == otherPid) DoNothing();
// section critique
wantIn[myPid] = false
}Expliquer ensuite de manière intuitive pourquoi ce code garantit un accès exclusif à la portion de code dite « section critique ».
Soit le programme suivant :
/* producer-consumer on 1-element buffer */
#include<stdio.h>
#include <stdlib.h>
#include<pthread.h>
#include <semaphore.h>
#define NITERS 5
static struct {
int buf; /* shared var */
sem_t full; /* sems */
sem_t empty;
} shared;
void
P(sem_t * sem) {
if (sem_wait(sem))
printf("P\n");
}
void
V(sem_t * sem) {
if (sem_post(sem))
printf("V\n");
}
/* producer thread */
void *
producer(void *arg)
{
int i, item;
for (i = 0; i < NITERS; i++) {
/* produce item */
/* write item to buf */
P(&shared.empty);
item = i;
printf("produced %d\n", item);
shared.buf = item;
V(&shared.full);
}
return NULL;
}
/* consumer thread */
void *
consumer(void *arg)
{
int i, item;
for (i = 0; i < NITERS; i++) {
/* read item from buf */
P(&shared.full);
item = shared.buf;
printf("consumed %d\n", item);
V(&shared.empty);
/* consume item */
}
return NULL;
}
int
main()
{
pthread_t tid_producer;
pthread_t tid_consumer;
/* initialize the semaphores */
sem_init(&shared.empty, 0, 1);
sem_init(&shared.full, 0, 0);
/* create threads and wait */
pthread_create(&tid_producer, NULL, producer, NULL);
pthread_create(&tid_consumer, NULL, consumer, NULL);
pthread_join(tid_producer, NULL);
pthread_join(tid_consumer, NULL);
exit(0);
}
/*
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int valeur);
int sem_wait(sem_t * sem);
int sem_trywait(sem_t * sem);
int sem_post(sem_t * sem);
int sem_getvalue(sem_t * sem, int * sval);
int sem_destroy(sem_t * sem);
sem_init() initialise le sémaphore pointé par sem. Le compteur associé au sémaphore est initialisé à valeur. L'argument pshared indique si le sémaphore est local au processus courant (pshared est zéro) ou partagé entre plusieurs processus (pshared n'est pas nulle). LinuxThreads ne gère actuellement pas les sémaphores partagés entre plusieurs processus, donc sem_init() renvoie toujours l'erreur ENOSYS si pshared n'est pas nul.
sem_wait() suspend le thread appelant jusqu'à ce que le sémaphore pointé par sem ait un compteur non nul. Alors, le compteur du sémaphore est atomiquement décrémenté.
sem_trywait() est une variante non bloquante de sem_wait(). Si le sémaphore pointé par sem a une valeur non nulle, le compteur est atomiquement décrémenté et sem_trywait() retourne immédiatement 0. Si le compteur du sémaphore est zéro, sem_trywait() retourne immédiatement en indiquant l'erreur EAGAIN.
sem_post() incrémente atomiquement le compteur du sémaphore pointé par sem. Cette fonction ne bloque jamais et peut être utilisée de manière fiable dans un gestionnaire de signaux.
sem_getvalue() sauvegarde à l'emplacement pointé par sval la valeur courrante du compteur du sémaphore sem.
sem_destroy() détruit un sémaphore, libérant toutes les ressources qu'il possédait. Aucun thread ne doit être bloqué sur ce sémaphore quand sem_destroy () est appelée. Dans l'implémentation LinuxThreads, aucune ressource ne peut être associée à un sémaphore, donc sem_destroy() ne fait actuellement rien si ce n'est vérifier qu'aucun thread n'est bloqué sur ce sémaphore.
*/Expliquez ce programme. Hint : ici le contrôle de la synchronisation se fait par un type de données abstrait appelé sémaphore qui est une variable entière non négative munie de deux opérations élémentaires non divisibles P et V (voir le code pour l'implémentation de P et V).
2-Appels système et tubes
Les exercices sur les tubes se font avec des tubes nommés. Ils permettent de faire de la communication entre différents exécutables. On crée un tube nommé (une « espèce de » fichier) sous la ligne de commande Unix avec la commande mkfifo MonTube. (faites un file MonTube puis un ls -al MonTube). A l'intérieur des fichiers C, on ouvre un tube nommé par la commande open(MyTube,...) et dans tous les fichiers qui veulent l'utiliser. Faites un man de mkfifo et aussi de open. Les écritures et lectures dans le tube se font par write(), read() respectivement.
2.1 Au moyen des primitives open, close, write et read, écrire un exécutable qui saisi un char et si c’est un caractère minuscule le passe à un autre exécutable qui l’affiche. On lancera le premier exécutable dans une fenêtre et le deuxième dans une autre.
2.2 On vous demande de créer trois exécutables. Le premier (exo2) saisit des entiers et les dirige dans un tube selon qui sont pairs ou impairs. Les deux autres exécutables (exo2.1 et exo2.2) reçoivent les entiers et en font la somme.
La démarche :
1- créer deux tubes avec la commande mkfifo dans une fenetre shell
2- lancer l'exécutable exo2 dans une fenêtre
3- lancer exo2.1 dans une autre fenêtre
3- lancer exo2.2 dans une autre fenêtre
4- taper des caractères dans la première fenêtre (-1 pour terminer)...ils apparaissent dans l'une ou l'autre des 2 autres fenêtres selon qu'ils sont pairs ou impairs. Lorsqu'on tape -1, on affiche la somme des entiers pairs dans la 2ème fenêtre et la somme des entiers impairs dans la troisième fenêtre.
Résultats d'exécution :
[cerin@taipei SE]$ mkfifo -m 777 pair [cerin@taipei SE]$ mkfifo -m 777 impair [cerin@taipei SE]$ gcc -o exo2 exo2.c [cerin@taipei SE]$ gcc -o exo2.1 exo2.1.c [cerin@taipei SE]$ gcc -o exo2.2 exo2.2.c [cerin@taipei SE]$ ./exo2 12 13 14 13 30 8 8 -1 [cerin@taipei SE]$Dans la 2ème fenêtre :
[cerin@taipei SE]$ ./exo2.1 somme partielle des entiers impairs = 13 somme partielle des entiers impairs = 26 [cerin@taipei SE]$Dans la 3ème fenêtre :
[cerin@taipei SE]$ ./exo2.2 somme partielle des entiers pairs = 12 somme partielle des entiers pairs = 26 somme partielle des entiers pairs = 56 somme partielle des entiers pairs = 64 somme partielle des entiers pairs = 72 [cerin@taipei SE]$2.3 Reprendre l’exercice précédent et retournez les sommes partielles à exo2 qui les affiche. De plus n’utilisez pas de mkfifo mais ouvrez de nouveaux tubes à l’intérieur de votre programme.
3- Les signaux
3.1 Ecrire un programme qui arme les signaux SIGINT et SIGQUIT et qui à chaque fois que l’on tape ctrl C incrémente une variable de 1 et qui sortira et affichera la valeur de la variable à la réception du signal SIGQUIT.
3.2 Ecrire un programme qui lit un entier et déclenche un signal pour calculer dans un premier handler la somme des entiers pairs et dans un deuxième handler la somme des entiers impairs. On termine la saisie par Ctrl D. On affiche alors les deux sommes partielles.
3.3 Process sets a handler for SIGUSR1, and suspends until any signal is received. If SIGUSR1 is received the handler is executed; for all other signals the handler is not executed. You can run this program with "% a.out &". The program prints its own processid. Then you can send a SIGUSR1 signal to it with :
% kill -USR1 processid
Sending any other signal will not invoke the handler and will have the usual behavior: will be ignored or will terminate the process.
3.4 Quel est le problème de conception avec le code suivant :
#include <stdio.h> #include <signal.h> void hd_int(int n) { signal(SIGINT, hd_int); printf(" %d capte\n",n); } main() { sigset_t ens_anc,ens_nv; signal(SIGINT,hd_int); sigemptyset(&ens_nv); sigaddset(&ens_nv,SIGINT); sigprocmask(SIG_SETMASK,&ens_nv,&ens_anc); sleep(10); switch(fork()) { case -1: perror("fork"); exit(1); case 0: sigprocmask(SIG_SETMASK,&ens_anc,NULL); sleep(1); exit(0); default: sigprocmask(SIG_SETMASK,&ens_anc,NULL); sleep(1); } }3.5 Ecrire un programme qui crée un fils avec une instruction fork(). Le père tue le fils s’il existe (voir l’instruction kill) et attend la fin de son exécution. Le fils est dans une boucle infinie qui fait un sleep(1);
3.6 /*sig2read2.c*/
Le père p0 crée 2 fils p1 et p2 communiquant par pipe (p1 écrit p2 lit sur un tube). p0 envoie un signal (SIGUSR1) a p2 sur un read bloquant. p2 doit exécuter le handler mais ne pas s'interrompre.
3.7 Faites un commentaire du code suivant : expliquez son fonctionnement.
#include<stdio.h> #include<signal.h> void hd_int(int n) { signal(SIGINT,hd_int); printf("Signal %d capte\n",n); } void hd_quit(int n) { signal(SIGQUIT,hd_quit); printf("Signal %d capte\n",n); } main() { sigset_t ens1; int i; signal(SIGINT, hd_int); signal(SIGQUIT, hd_quit); printf("pid %d\n",getpid()); sigemptyset(&ens1); for(i=1;i<NSIG;i++) { if(i!=2) sigaddset(&ens1,i); } if(sigsuspend(&ens1)== -1) pause(); printf("Fini\n"); }4- Ordonnancement
L'algorithme d'ordonnancement des processus le plus simple est l'algorithme du premier entré, premier sorti (FCFS: first Come, Fist Serve). Les processus sont ordonnancées dans l'ordre où ils sont reçus. Cet algorithme n'est pas préemptif : une tâche qui a débuté, termine avant que l'on passe la main à la suivante.
Quels sont les inconvénients de cette approche si les processus (tâches) à accomplir comportent beaucoup de requêtes d'I/O ?
L'algorithme du travail le plus court d'abord (SJF: Shortest Job first) est également non-préemptif. Il sélectionne le processus dont il suppose que le temps de traitement sera le plus court. En cas d'égalité, l'ordonnancement FCFS peut être utilisé.
Quels sont les inconvénients de cette approche si les processus (tâches) à accomplir comportent beaucoup de travaux de courtes durées et peu de travaux de longues durées ?
L'algorithme du temps restant le plus court (SRT: Shortest Remaining Time) est la version préemptive de l'algorithme SJF. Chaque fois qu'un nouveau processus est introduit dans le pool de processus à ordonnancer, l'ordonnanceur compare la valeur estimée de temps de traitement restant à celle du processus en court d'ordonnancement. Si ce temps est inférieur, le procesus en cours d'ordonnancement est préempté.
Quels sont les inconvénients de cette approche si les processus (tâches) à accomplir comportent beaucoup de travaux de courtes durées et peu de travaux de longues durées ?
L'algorithme à tourniquet (RR: Round robin) est un algorithme préemptif qui sélectionne le processus qui attend depuis le plus longtemps. Après un quantum de temps spécifié, le processus en cours d'exécution est préempté et une nouvelle sélection est effectuée. Si le quantum de temps est très court, la réponse du sytème est bonne. Cependant, plus on change souvent de contexte, plus les surcoûts peuvent prendre de l'importance (d'où l'importance d'avoir du matériel dédié pour implémenter efficacement cette notion).
L'algorithme avec priorité requiert qu'une valeur (dite de priorité) soit associée à chaque processus. Le processus sélectionné est celui avec la plus haute priorité. C'est l'algorithme FCFS qui est utilisé en cas d'égalité. L'ordonnacement des priorités peut être préemptif ou non.
Les mécanismes d'attribution des priorités sont très variables : bassés sur la caractéristique des processus (utilisation de la mémoire ; fréquence des I/O), sur l'utilisateur qui exécute le processus (les processus root ont une priorité plus élevée) ou encore sur les paramètres que l'utilisateur ou l'administrateur peut spécifier.
4.1 Exercice sur les performances
Soit les données d'ordonnancement suivantes :
|
Processus |
Date d'arrivée |
Temps de traitement |
|
A |
0 |
5 |
|
B |
1 |
2 |
|
C |
2 |
5 |
|
D |
3 |
3 |
Quel est le déroulement de l'exécution des processus pour l'algorithme SRT ? (on préempte à chaque unité de temps). Même question pour l'algorithme du tourniquet.
Le temps de rotation de chaque processus peut être calculé en soustrayant la date à laquelle le processus a été introduit dans le système à la date à laquelle celui-ci a pris fin. Calculez les temps de rotation des 4 processus précédents et pour les deux algorithmes (SRT et RR).
Le temps de rotation moyen est alors calculé en faisant la somme des temps de rotation et en divisant par le nombre de processus concernés. Calculez les deux temps moyen. En déduire l'agorithme le « meilleur ».
4.2 Exercice sur les algorithmes d'ordonnancement
Avec les processus répertoriés dans le tableau qui suit, dessinez un schéma illustrant leur exécution à l'aide des algorithmes FCFS, SJF, SRT, RR (quantum = 2), RR (quantum = 1).
|
Processus |
Date d'arrivée |
Temps de traitement |
|
A |
0,00 |
3 |
|
B |
1,001 |
6 |
|
C |
4,001 |
4 |
|
D |
6,001 |
2 |
Calculez également pour chaque algorithme les temps moyens de rotation.
Le temps d'attente peut être calculé en soustrayant la durée d'exécution du temps de rotation. Calculez les temps d'attente pour les 4 processus précédents.
4.3 Autres algorithmes d'ordonnancement
a) Considérons de nouveaux la politique SJF. A la différence de précédemment, ici le temps de traitement de la tâche Ti n'est pas connue à l'avance mais il est estimé en fonction de la durée d'exécution précédente de la tâche. L'estimation peut être faite par :
![]()
![]() (a
est une constante comprise entre 0 et 1)
(a
est une constante comprise entre 0 et 1)
On considère a=0.8 et T0=2. Tracer les deux fonctions correspondantes aux deux estimations ci-dessus. Considérez alors qu'une seule et même tâche arrive dans le système toutes les 2 unités de temps (c'est périodique) et dure 1.5 unité de temps. Quel sera l'ordonnancement de ces tâches si on considère la première puis la deuxième estimation ?
b) Considérons maintenant la politique HRRN (Highest Response Time Next). Cette politique calcule la quantité suivante RR=(w+s)/s où w est le temps passé à attendre le processeur et s est l'estimation du temps d'exécution ou de service (calculé au moyen des formules ci-dessus). La règle d'ordonnancement est alors la suivante : quand le processus courant est terminé (ou bloqué), choisir le processus avec la plus grande valeur RR.
Cette approche se caractérise par la prise en compte de « l'âge » des processus tout en accordant plus d'importance aux « petits » processus (« un petit s produit un grand RR »).
Reprenez l'exemple du a) et donnez l'ordonnancement.
5- Calcul du nombre de processus créés.
Dans le cours, il y a un exemple d'une boucle pour dans laquelle on a une instruction fork(). Nous avons remarqué que si on enlève l'instruction exit ou break dans le fils, alors il n'y a pas n processus de crées mais plus.
On vous demande d'exprimer C(n) (nombre de processus créés en fonction de la borne n de la boucle pour) en fonction de n. Pour cela, considérez les cas n=1, n=2, n=3 puis conjecturez une solution pour C(n). Montrez alors l'héritage de la propriété c.à.d C(n) => C(n+1).
6- Synchronisation
Soit un système composé de deux processus cycliques Exécution et Impression, et d'un tampon AVIS de n cases. Le tampon AVIS est géré de façon circulaire.
Le processus Exécution exécute une requête de travail et transmet ensuite au processus Impression un ordre d'impression de résultats déposé dans le tampon AVIS. La case de dépôt est repérée par un index i de dépôt, initialisé à 1. Les dépôts s'effectuent depuis la case 1 jusqu'à la case N, puis retour à la case 1 (gestion circulaire).
Le processus Impression prélève les ordres d'impression déposés dans le tampon AVIS et exécute ceux-ci. La case de retrait est repérée par un index j de retrait, initialisé à 1. Les retraits s'effectuent depuis la case 1 jusqu'à la case N, puis retour à la case 1 (gestion circulaire).
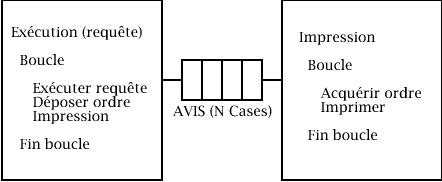
Programmez la synchronisation des deux processus à l'aide des sémaphores et des variables nécessaires à la gestion des tampons.
7- Parallélisme / concurrence
Supposons que le tableau B[0,j] ait été rempli avec les entiers 1...n. Supposons que l'on dispose de n processeurs et que l'instruction pardo permet d'exécuter des instructions en parallèle (en « vrai » parallélisme, pas en temps partagé !). Que va t'on calculer dans le tableau C avec l'algorithme ci-dessous ? (on suppose de plus que n est une puissance de 2)

Donnez les contenus du tableau C entre chaque itération.